目录
- 安装 LoRa 插件 Additional Networks
- 安装 ControlNet
- Jupyter Notebook
- 模型训练工具 Kohya_ss
- After Detailer | 面部、手部修复神器
- prompt-all-in-one 提示词翻译补全 (自动翻译)
- SixGod 提示词插件
- Inpaint Anything 蒙版换装换脸
- Segment Anything 识别分割图片中的物体
- ultimate SD upscale 图片放大
- Tiled Diffusion
- sd-webui-mov2mov(AI 视频转换)
- Deforum
- sd-dynamic-thresholding
- Stable-Diffusion-Webui-Civitai-Helper
- Wd14 Tagger:提示词反推
- 中英文双语界面
- LLuL
- 动态 CFG
- multidiffusion-upscaler
- preset_utils
- regional-prompter
- Canvas Zoom | 画布缩放
- Regional Prompter | 区域提示器
- Style Selector for SDXL 1.0 | SDXL 1.0 的风格选择器
- Aspect Ratio selector | 宽高比选择器
安装 LoRa 插件 Additional Networks
使用 Lora 必不可少的插件,Additional Networks 可以用来控制 checkpoint+LoRa 或者多个 LoRa 模型生成混合风格的图像,并且可以设置 Lora 模型的 Weight。安装方式如下:
打开 stable-diffusion-webui,点击【Extensions】-【Install from URL】输入 https://ghproxy.com/https://github.com/kohya-ss/sd-webui-additional-networks.git
然后点击【Install】等待安装,直到在【Installed】中显示,然后直接用命令重启 stable-diffusion-webui(不是 reload webui),强烈推荐所有插件安装完成都命令重启 stable-diffusion-webui,可以免去很多麻烦。
最后点击【Setting】-【Additional Networks】输入 LoRa 文件夹的绝对路径,如/root/stable-diffusion-webui/models/Lora(示例,请填写你的系统路径),然后【Reload UI】等待重启完成。
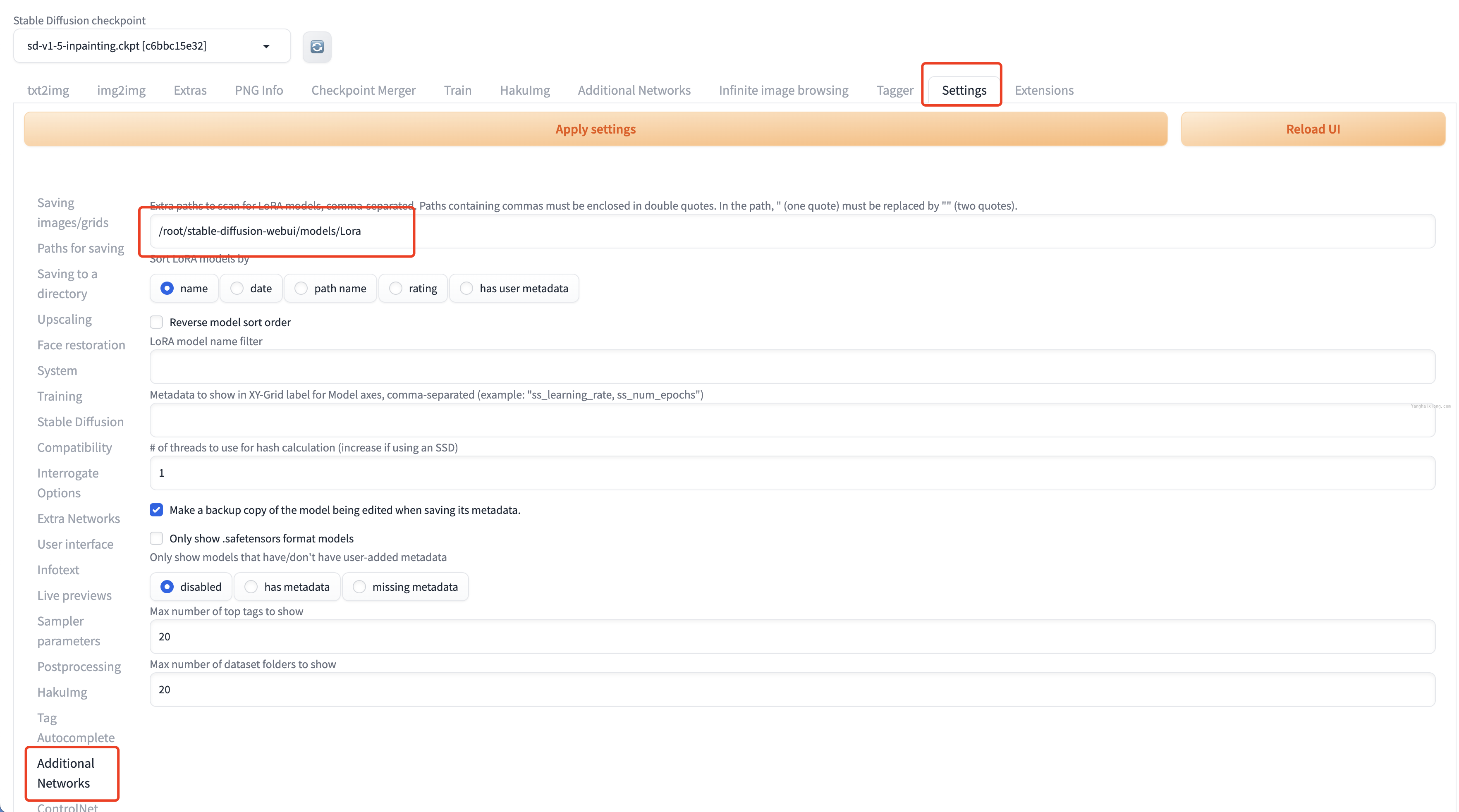
然后可以在【txt2img】或【img2img】中选择 Lora 模型并设置权重使用。
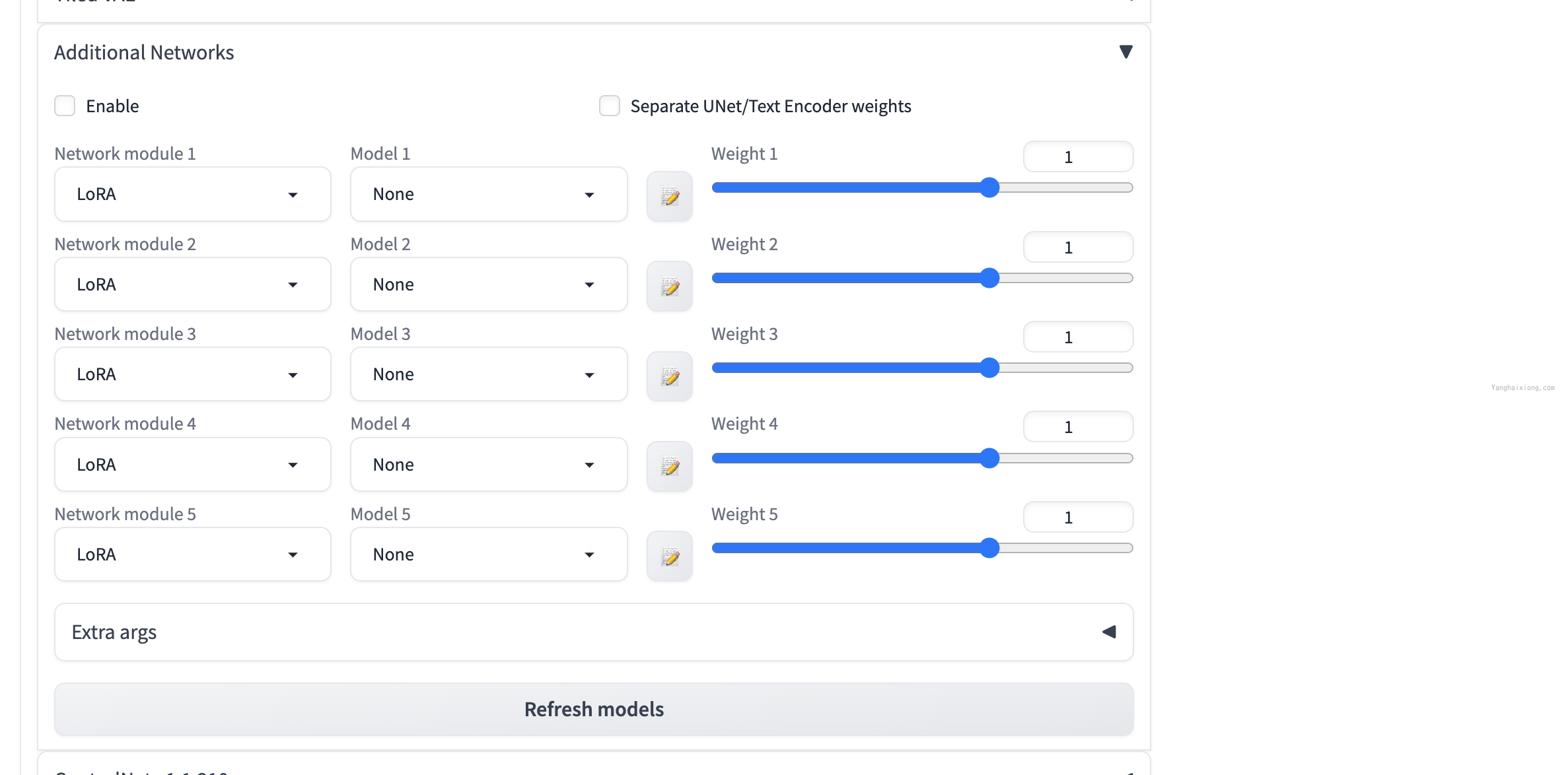
安装 ControlNet
作为 Stable Diffusion 必装插件,ControlNet 允许用户对生成的图像进行精细的控制,以获得更好的视觉效果,ControlNet 让 AI 绘画的可控性有了质的突变,让 AGIC 真正的可以投入生产使用。
打开 stable-diffusion-webui,点击【Extensions】-【Install from URL】输入 https://ghproxy.com/https://github.com/Mikubill/sd-webui-controlnet.git
然后点击【Install】等待安装,直到在【Installed】中显示,然后直接用命令重启 stable-diffusion-webui(不是 reload webui)。
由于 controlNet 会使用很多模型,所以在重启的时候会默认下载,如果下载失败或超时,需要手动下载到 controlnet 目录。
访问 huggingface.co 找到 controlnet 的地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
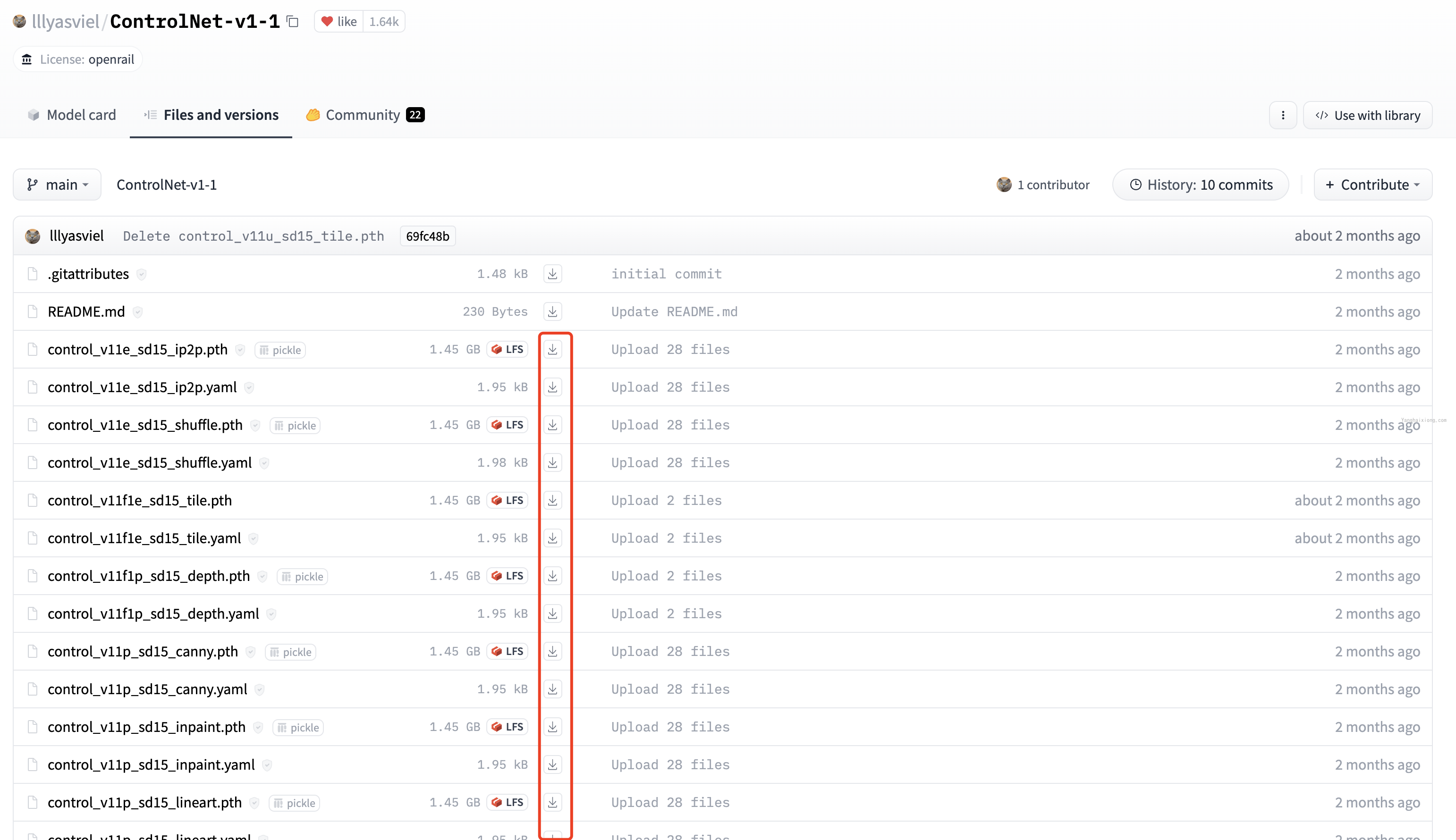
手动下载上面模型文件到 stable-diffusion-webui/extensions/sd-webui-controlnet/models 目录,查看已下载 controlnet 模型:

下载完成,重启 stable-diffusion-webui 即可在【txt2img】或【img2img】使用。
Jupyter Notebook
Jupyter Notebook 是一个基于网页的交互环境,可以用来编辑、运行 Python 代码,可视化看到运行结果。同时提供了基础的文件树操作功能等。
在上述文章中,安装了 Anaconda,直接使用以下命令运行 notebook
jupyter notebook --allow-root --NotebookApp.token='设置你的token'
访问 IP+8888 端口,可以开始使用 notebook
远程访问服务器 Jupyter Notebook 的三种方法
方法 1. ssh 远程使用 jupyter notebook
- 在远程服务器上,启动 jupyter notebooks 服务:
jupyter notebook --ip=0.0.0.0 --no-browser --allow-root
- 在本地终端中启动 SSH:
ssh -N -f -L localhost:8888:localhost:8889 username@serverIP
其中:-N 告诉 SSH 没有命令要被远程执行;-f 告诉 SSH 在后台执行;-L 是指定 port forwarding 的配置,远端端口是 8889,本地的端口号的 8888。
注意:username@serverIP 替换成服务器的对应账号。
- 最后打开浏览器,访问:http://localhost:8888/
方法 2. 利用 jupyter notebook 自带的远程访问功能
官方指南在此:官方指南
- 生成默认配置文件
jupyter notebook --generate-config - 生成访问密码 (token)
终端输入ipython,设置你自己的 jupyter 访问密码,注意复制输出的sha1:xxxxxxxx密码串
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'sha1:xxxxxxxxxxxxxxxxx'
- 修改
./jupyter/jupyter_notebook_config.py中对应行如下
c.NotebookApp.ip='*'
c.NotebookApp.password = u'sha:ce...刚才复制的那个密文'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #可自行指定一个端口, 访问时使用该端口
- 在服务器上启动
jupyter notebook
jupyter notebook - 最后打开浏览器,访问:http://ip:8888/
方法 3
配置自己的 config 文件,如 ./jupyter/jupyter_notebook_config_backup.py
jupyter notebook --config ./jupyter/jupyter_notebook_config_backup.py
模型训练工具 Kohya_ss
Kohya_ss 是公认推荐训练 Stable Diffusion 模型的可视化工具,尤其在 windows 平台支持比较好,经过尝试在 linux 直接使用可能会遇到各种环境原因的问题,
方法 1. dcker 安装
先按照 docker 官方文档安装好 docker,Ubuntu 安装 docker 文档:https://docs.docker.com/engine/install/ubuntu/
由于在 docker 容器中需要使用 GPU 资源,所以还需要先安装 NVIDIA Container Toolkit
sudo apt-get update \
&& sudo apt-get install -y nvidia-container-toolkit-base
# 查看是否安装成功
nvidia-ctk --version
然后下载 kohya_ss:
git clone https://github.com/bmaltais/kohya_ss.git
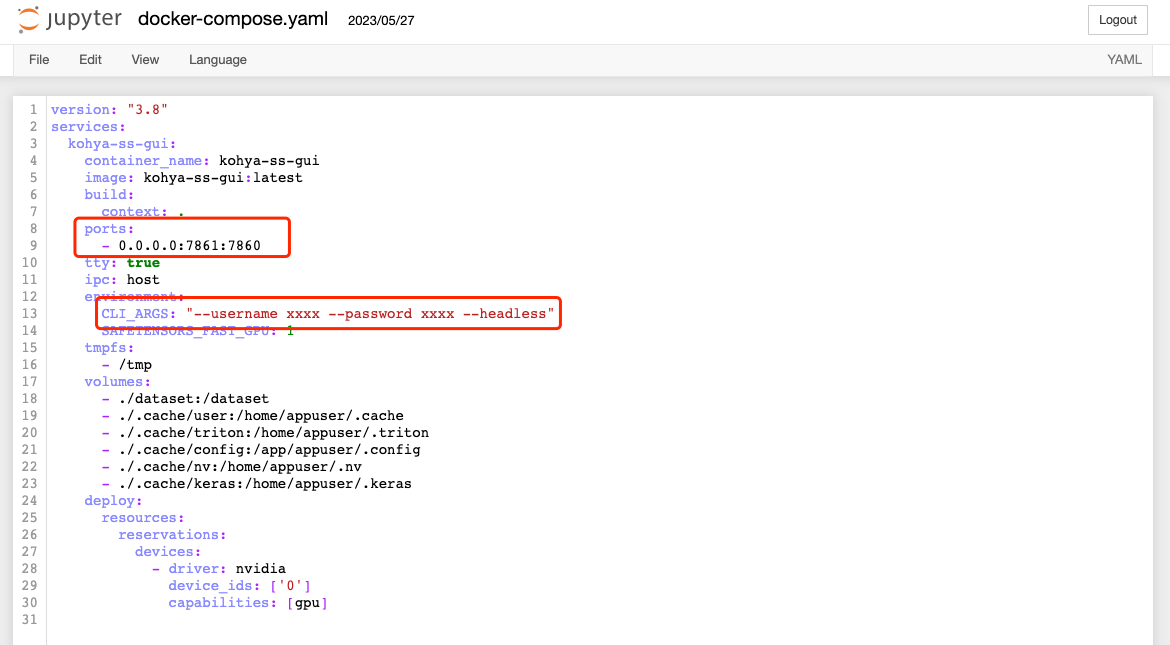
如下图,修改 kohya_ss/docker-compose.yaml 文件端口为 0.0.0.0:7861:7860(将 kohya_ss 的 7860 端口映射到宿主机的 7861 端口,因为 7860 会被 Stable Diffusion WebUI 占用),
启动参数设置为 "--username xxxx --password xxxx --headless",注意替换 xxxx 为需要设置的账号密码
然后执行
docker compose build # 首次执行需要build
docker compose run --service-ports kohya-ss-gui
过程中会从 huggingface.co 下载模型文件,如果下载失败,可以尝试手动下载到目录 kohya_ss/.cache/user/huggingface/hub/models–openai–clip-vit-large-patch14/snapshots/8d052a0f05efbaefbc9e8786ba291cfdf93e5bff,最后的 hash 值注意改成对应的版本。
下载地址 https://huggingface.co/openai/clip-vit-large-patch14/tree/main,注意下载全部文件
下载完成,然后访问端口 +7861 端口,可以开始使用 Kohya_ss 训练模型了。
方法 2. Conda 环境安装
使用 conda 创建虚拟环境,避免在 kohya_ss 安装过程,重新安装的 pytorch 等于 stable diffusion 冲突。
conda create -n ks python==3.10.13
参考 kohya_ss git安装文档, 执行如下命令:
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
chmod +x ./setup.sh
./setup.sh
./gui.sh --share # 公网可访问
./gui.sh --listen 0.0.0.0 --server_port 7861 --inbrowser --share # 局域网可访问
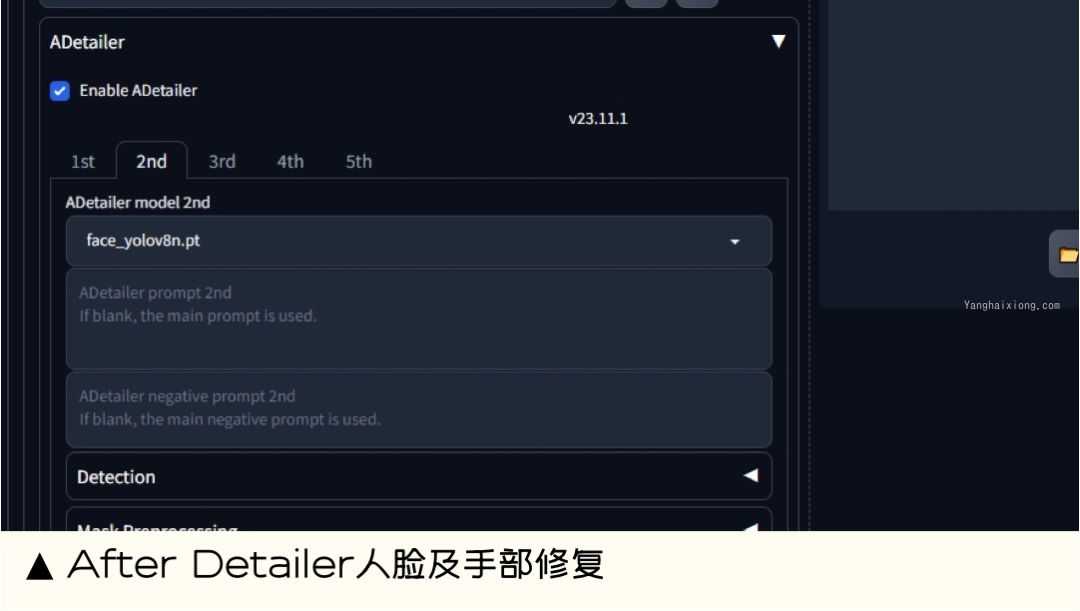
After Detailer | 面部、手部修复神器
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题。
下载链接:https://github.com/Bing-su/adetailer.git
prompt-all-in-one 提示词翻译补全 (自动翻译)
能做什么:prompt-all-in-one 提示词翻译补全可以帮助英文不好的用户,快速弥补英文短板。其中包含,中文输入自动转英文、自动保存使用描述词、描述词历史记录、快速修改权重、收藏常用描述词、翻译接口可以多种选择、一键粘贴删除描述词等。
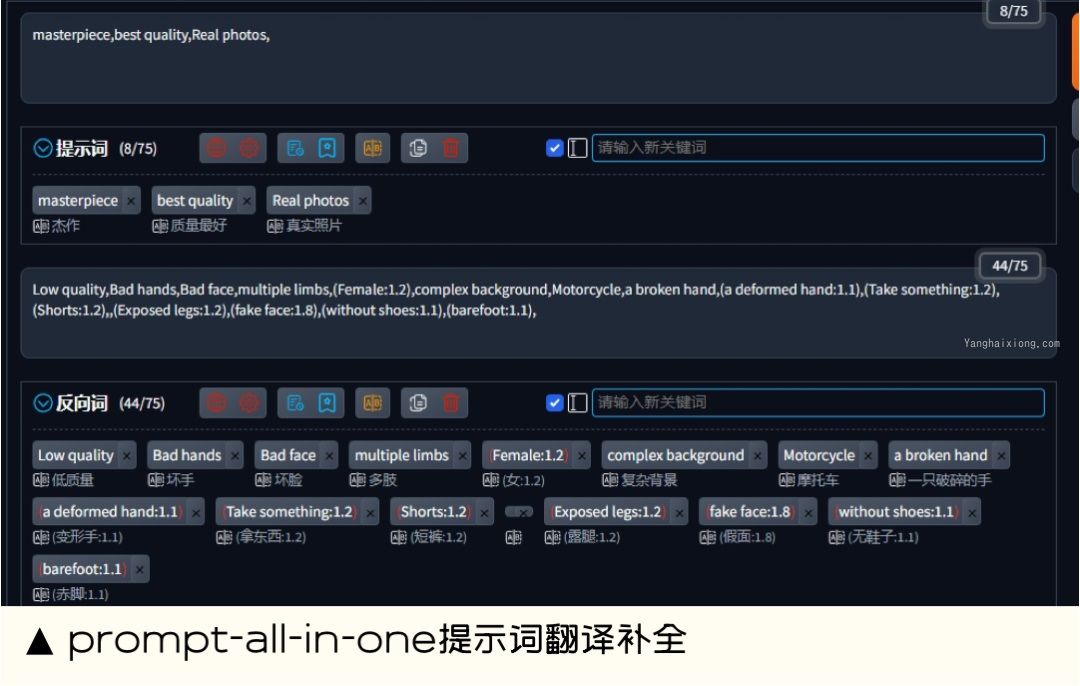
扩展地址:https://github.com/Physton/sd-webui-prompt-all-in-one
SixGod 提示词插件
能做什么:SixGod 提示词插件可以帮助用户快速生成逼真、有创意的图像。其中包含,清空正向提示词 " 和 " 清空负向提示词、提示词起手式包含人物、服饰、人物发型等各个维度的提示词、一键清除正面提示词与负面提示词、随机灵感关键词、提示词分类组合随机、动态随机语法等。
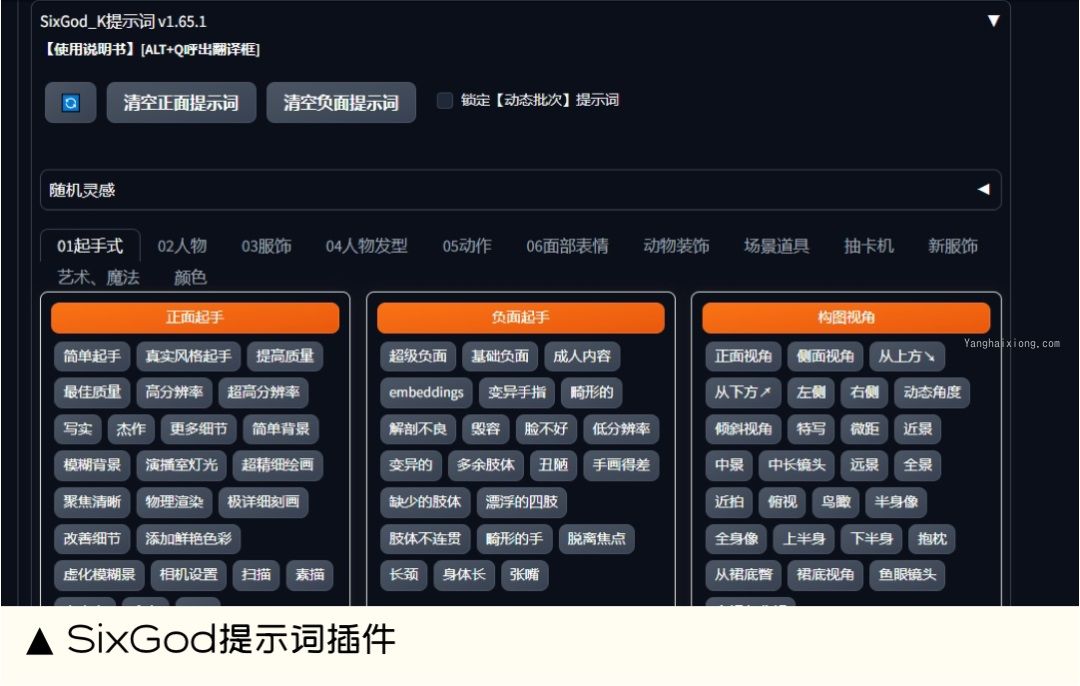
扩展地址:https://github.com/thisjam/sd-webui-oldsix-prompt
Inpaint Anything 蒙版换装换脸
能做什么:Inpaint Anything 是一款强大的图像编辑工具,可用于删除和替换图像中的任何内容。它使用人工智能来自动识别和修复图像中的缺陷,无需使用遮罩。删除图像中的不需要的对象或瑕疵、修复图像中的损坏、替换图像中的对象或背景、创建创意图像效果。
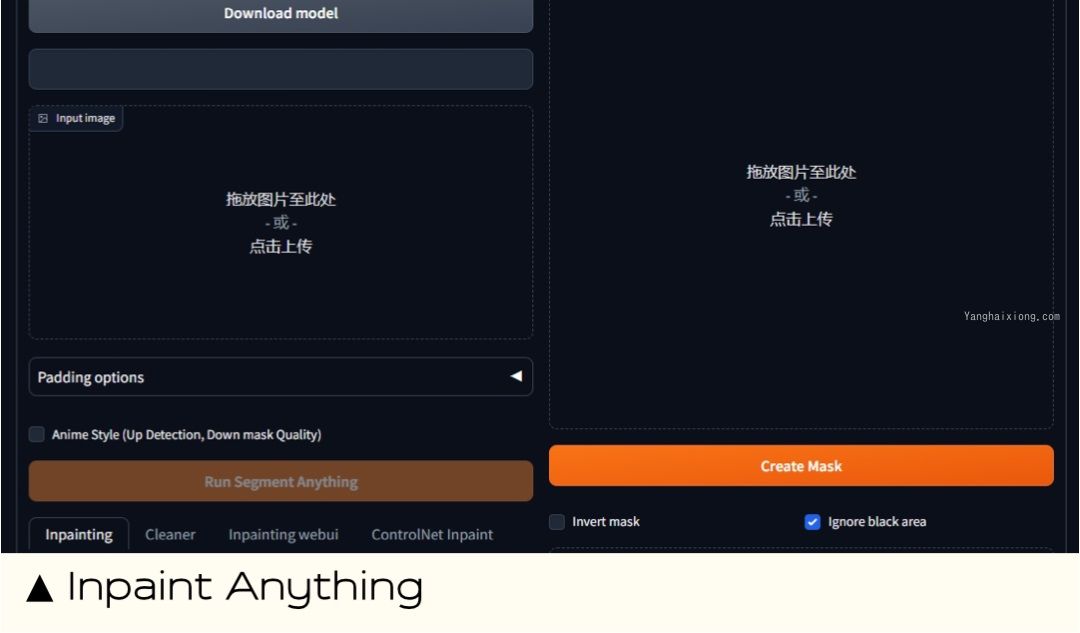
扩展地址:https://github.com/Uminosachi/sd-webui-inpaint-anything
Segment Anything 识别分割图片中的物体
能做什么:Segment Anything 是一款强大的图像分割工具,可用于自动识别和分割图像中的不同对象。类似于 controlnet 中的 SEG 语义分割,但 Segment Anything 是功能更强大、准确性更高、易用性也更高的图像分割工具,但学习成本更高。
扩展地址:https://github.com/facebookresearch/segment-anything.git
ultimate SD upscale 图片放大
能做什么:Ultimate SD Upscale 是一款强大的图像超分辨率工具,可用于将低分辨率图像提升到高分辨率、减少噪声和模糊。Ultimate SD Upscale 使用的超分辨率模型是基于深度学习的,因此具有较高的准确性。
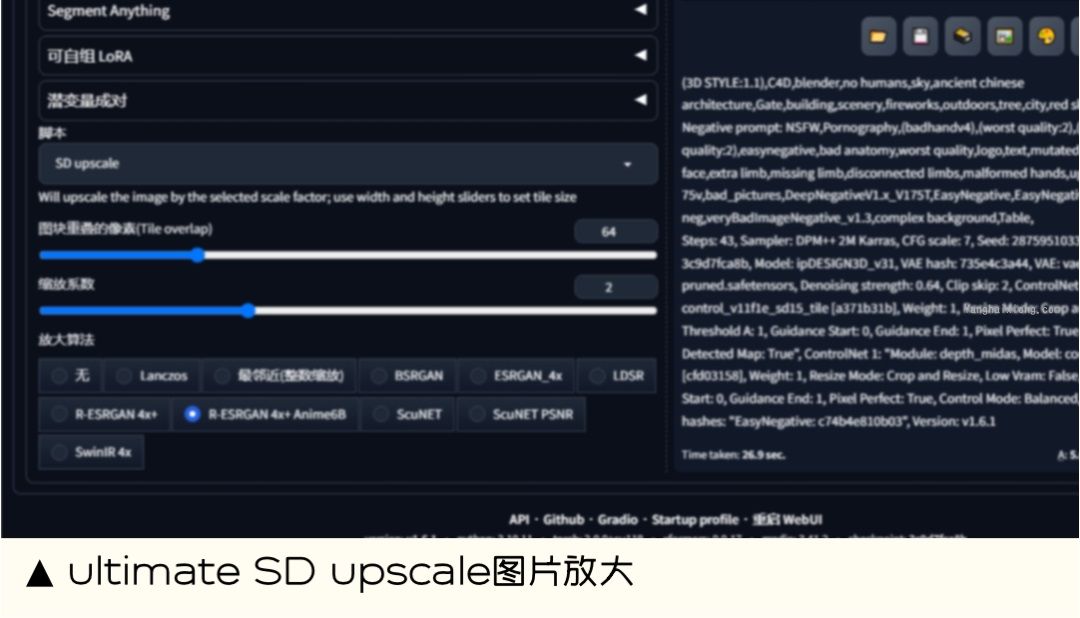
扩展地址:https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
Tiled Diffusion
能做什么:Tiled Diffusion 同样是图像超分辨率、修复图像瑕疵的工具。Tiled Diffusion 适合小显存,速度更快,细节添加更可控,也不容易崩坏。
扩展地址:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
本人用 Ultimate SD Upscale 最多,因为它相对更有发挥空间。而 Tiled Diffusion 是可以让图片看起来更逼真。、
sd-webui-mov2mov(AI 视频转换)
参数如下:感觉没有 40 显卡玩不了,如果显卡比较好,可以试试(movie frame 为每秒视频帧数)
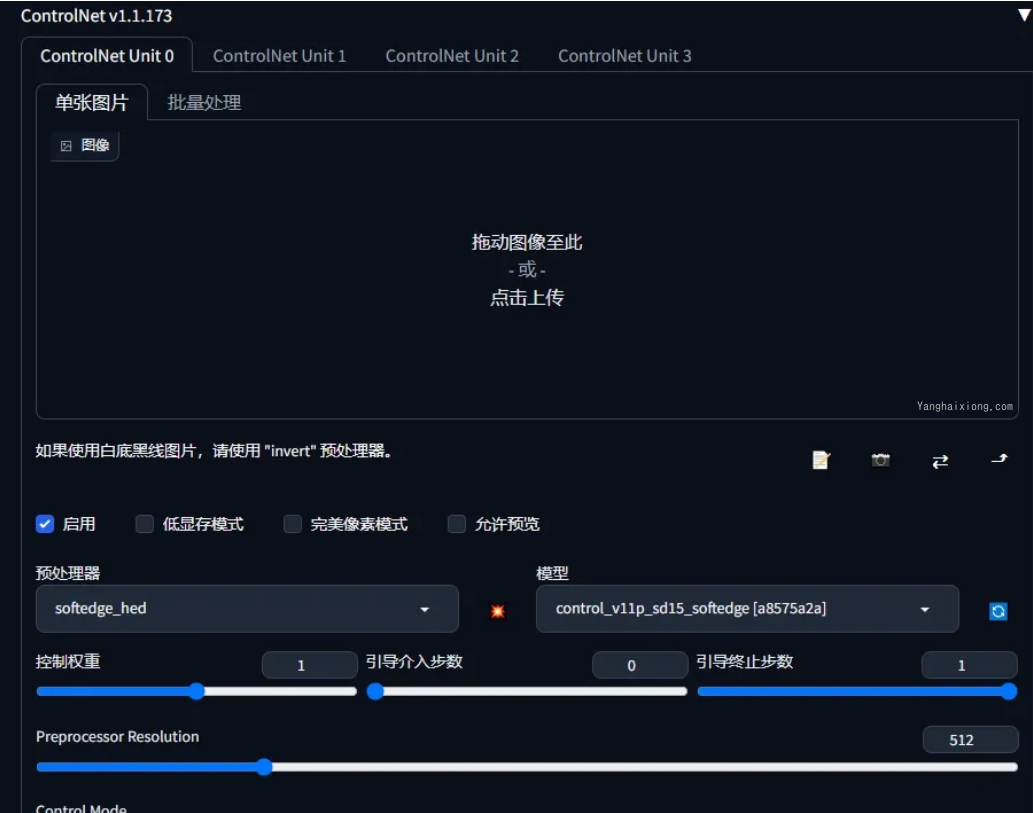
Deforum
使用参数如下,我只给出改了的部分,其他默认,最大帧数就是你要制作多少帧的视频,模型可以选择在第几帧开始使用哪个大模型,必须自已已经安装的,图片大小自己看着办,显卡好可以往上调
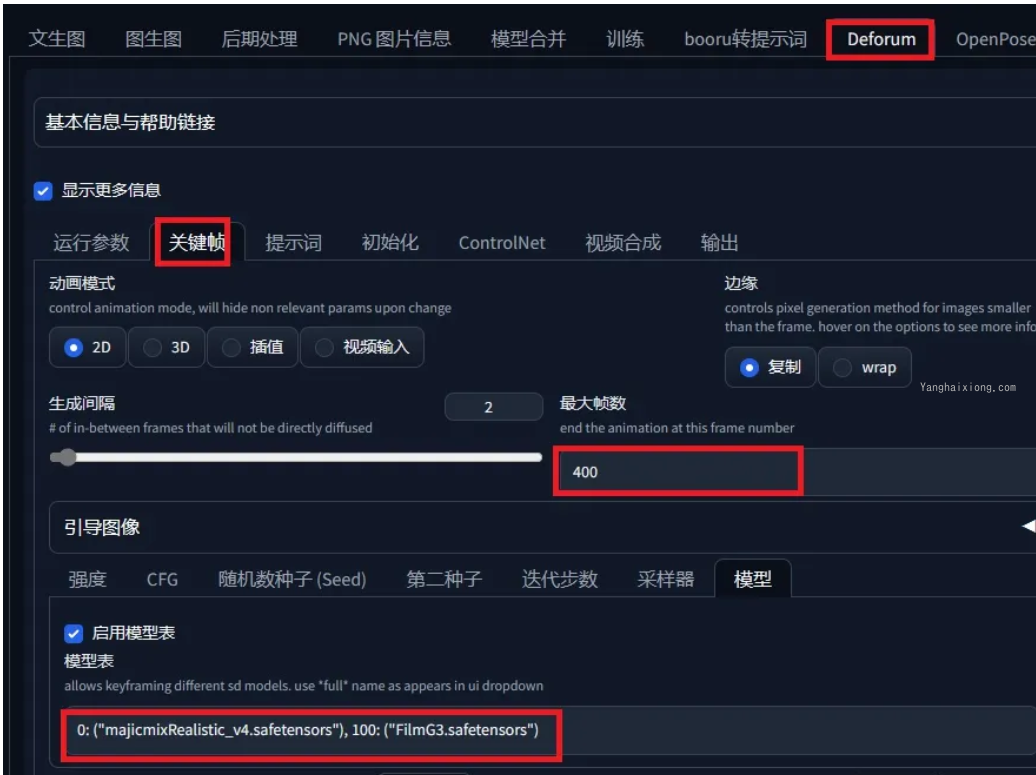
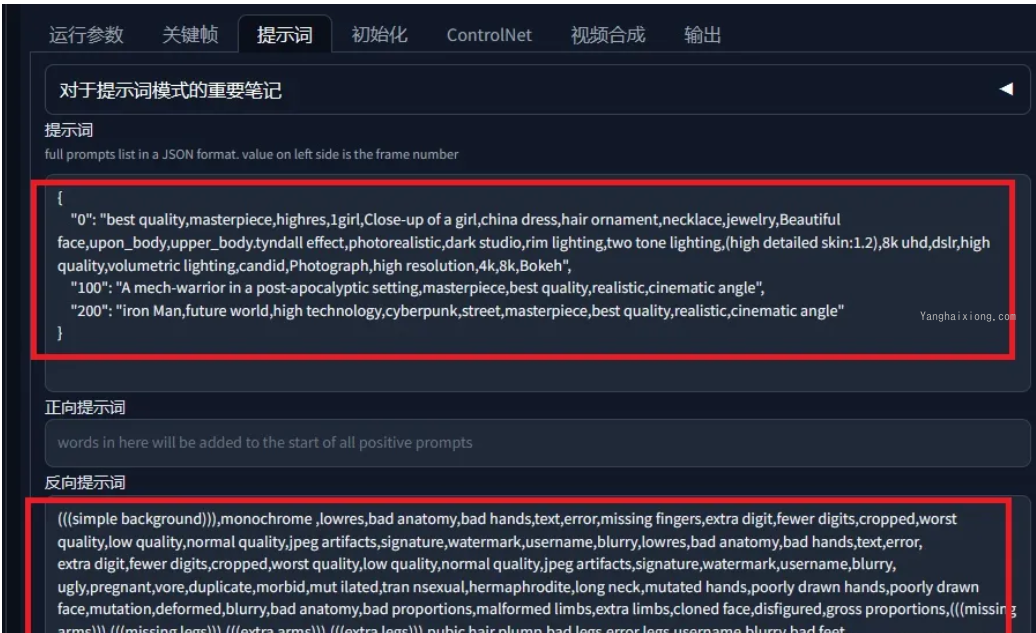
提示词我在,第 0,100,200 帧分别写了提示词,如果要改,按照格式改
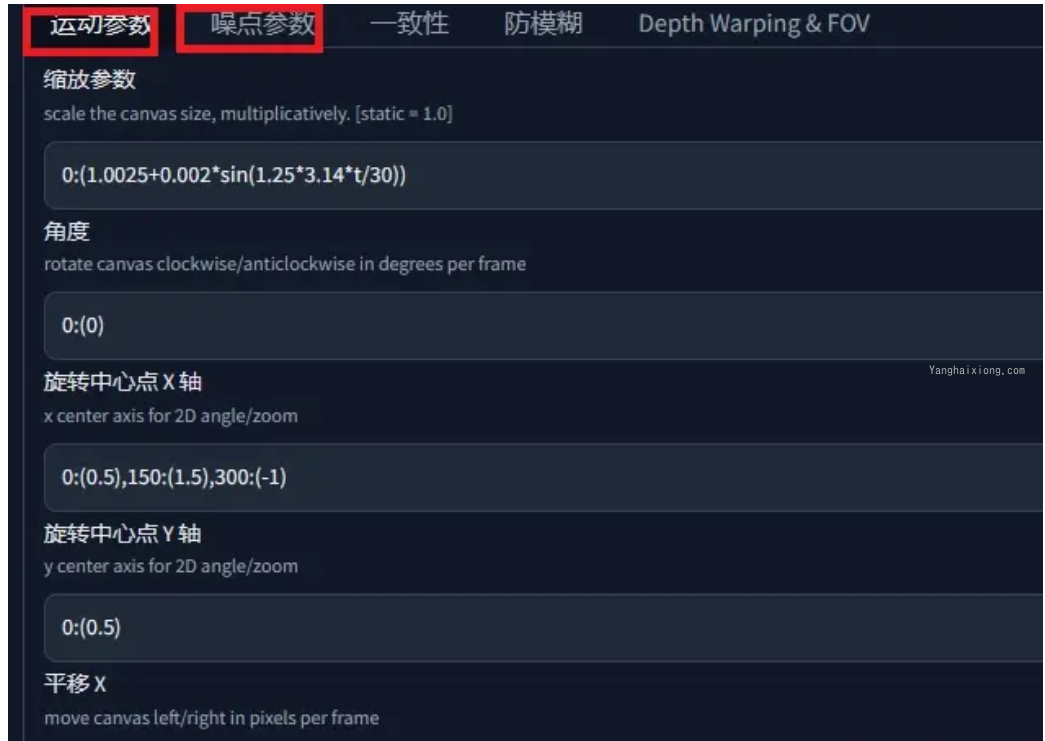
运行参数就是控制镜头移动,xy 控制上下左右,噪声越小,图片细腻度越高
sd-dynamic-thresholding
支持使用更高的 CFG 比例而不会出现崩坏问题
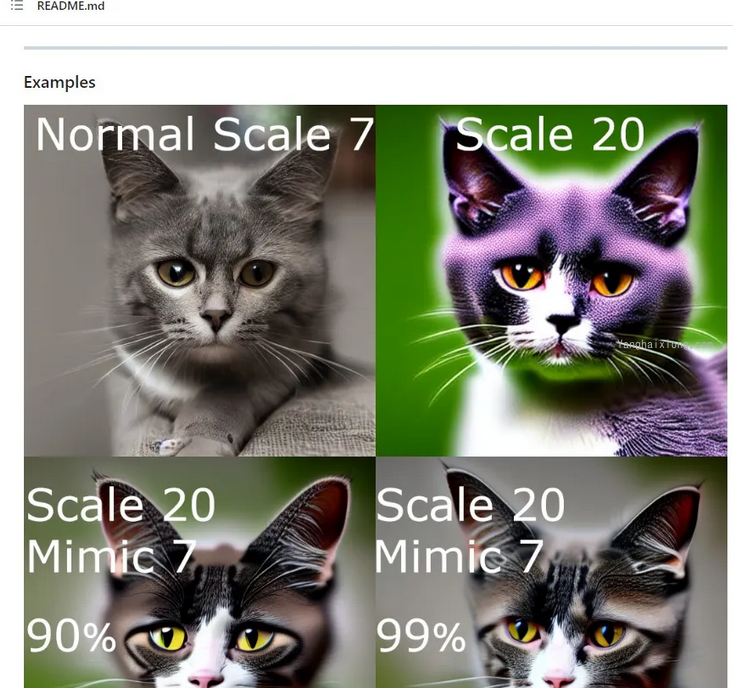

网址:https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
Stable-Diffusion-Webui-Civitai-Helper
网址:https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper.git
Wd14 Tagger:提示词反推
插件地址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger
推荐安装方式:从 git 网址安装
Wd14 Tagger 插件可以从上传的图像中识别并提取内容关键词,方便我们生成类似的图像。安装完成后上传一张图像,然后选择一个反推模型(一般使用 wd14-vit-v2.git),点击 Interregats 进行反推,就能得到关于图像的一组提示,并显示每个关键词的相关性权重。
相关功能:
- 阈值:设定权重值范围,超过此权重值的提示词才会显示出来;
- 可以批量处理图片,并将提示词批量导出,训练 lora 模型时可以用来为图片批量打标签;
- 使用结束后,记得点击下方的 ” 卸载所有反推模型 “,不然模型会占用很高的显存。

Images browser:图库浏览器
插件地址:https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
推荐安装方式:从 git 网址安装
Images browser 插件让我们能轻松直观的查看、管理所有用 WebUI 生成的图像,比在根目录的 Outputs 文件夹中查看要方便很多。安装完成后,点击插件的 " 首页 " 选项,即可加载所有生成的图像。

相关功能:
- 按文生图、图生图、后期处理、收藏夹等分类查看所有生成图片;可以按指定条件排序;可以按提示词搜索对应图片;可以批量删除图片;
- 点击一张图像,可以查看点击图像的生成信息(正负提示词、模型、尺寸等各项参数);再次点击可以全屏查看,通过键盘左右按键快速浏览;
- 对图像进行评级打分,按分数进行筛选;
- 将喜欢的图像添加到收藏夹,进行单独管理;
- 将图片及相关信息快速复制到文生图、图生图界面。

Tagcomplete:提示词自动补全/翻译
插件网址及使用教程:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
推荐安装方式:从 git 网址安装;从可用拓展列表安装
下载补充 Tag 词库:http://www.123114514.xyz/WebUI/Tag(文末有安装包)
Tagcomplete 的功能包括:
- 直接输入中文,调取对应的英文提示词;
- 根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中。
安装成功后,可以下载一个补全的 tag 词库,效果会更好,具体操作如下:

中英文双语界面
中英文双语界面是操作 Stable Diffusion 的最佳选择,它既可以帮助理解界面的中文意思,又可以在学习英文教程时更加得心应手。
安装方法:
- 下载中文扩展:https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
- 下载双语扩展:https://github.com/journey-ad/sd-webui-bilingual-localization
- 按照之前的教程中的任意一种方法安装这两个扩展

- 在 Stable Diffusion 的设置中选择中文界面,点击应用设置并重新加载界面
重启 Stable Diffusion 后,你将看到中英文双语的界面。
LLuL
https://github.com/hnmr293/sd-webui-llul
//局部提升绘画细节

动态 CFG
https://github.com/mcmonkeyprojects/sd-dynamic-thresholding
//动态 CFG,提升出图效果,必备的好插件。
详细介绍看我的博文《推荐一个能大幅提升StableDiffusion出图效果的小插件ynamic-thresholding》
multidiffusion-upscaler
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
//放大、分区域等众多功能,也是一款强大的混合插件。


preset_utils
https://github.com/Gerschel/sd_web_ui_preset_utils
//预设保存,不但可以保存魔法,还能保存完整的设置,对于经常做同类风格图片的人,兼职是福音。
regional-prompter
https://github.com/hako-mikan/sd-webui-regional-prompter //分区域精准生成。
功能类似 Latent couple。
https://github.com/opparco/stable-diffusion-webui-two-shot
实现效果如下图:

Canvas Zoom | 画布缩放
当我们在使用局部重绘的时候,画布的编辑非常头疼,体验很差。
Canvas Zoom 画布缩放可以非常方便的支持我们的日常操作,缩放、全屏、画笔调整等。
下载链接:https://github.com/richrobber2/canvas-zoom
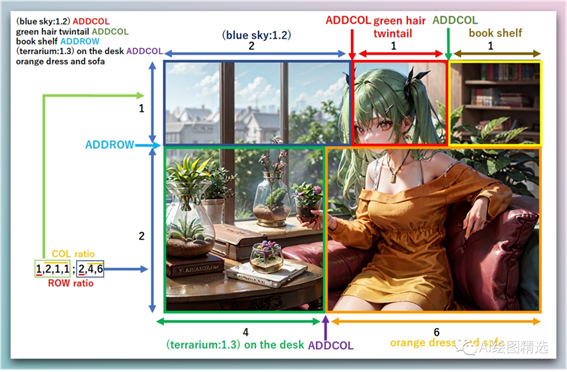
Regional Prompter | 区域提示器
区域提示器允许我们将图像分成几个部分并为每个部分设置独特的提示词。提供了极大的灵活性:比如可以准确定位对象并为图像的某些部分选择特定颜色,而无需更改其余部分。
下载链接:https://github.com/hako-mikan/sd-webui-regional-prompterCopied
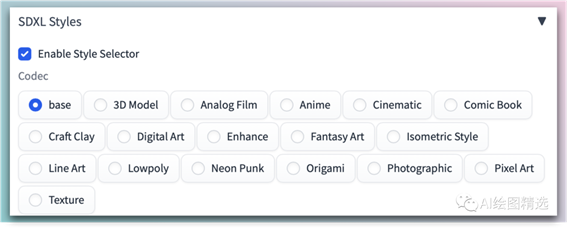
Style Selector for SDXL 1.0 | SDXL 1.0 的风格选择器
这个插件我们在前面的教程已经介绍过了。它能够支持通过选择出图风格自动生成对应风格的图。
下载链接:https://github.com/ahgsql/StyleSelectorXL
Aspect Ratio selector | 宽高比选择器
如果你准备在各自媒体平台发 SD 出的图,那么这个插件非常适合你,它可能快速的根据不同的分辨率的比例在调整宽高。不需要我们挨个的调整长宽了。
下载地址:https://github.com/alemelis/sd-webui-ar