目录
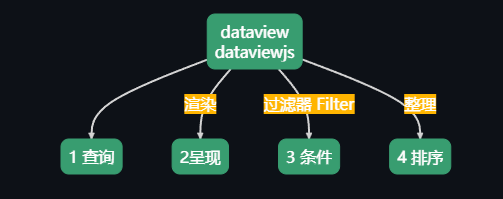
dataview
无论 dataview 也好,dataviewjs 也罢,都必须遵循一个逻辑流程:
dataview常用命令
From 来源从哪里查
[!tips] 提示
首先:指定查询来源,从哪个文件夹,从哪些标签
- 标签:从一个或多个标签范围内查询,语法是
#标签名,井号不能省略。 - 文件夹:从文件夹(及其所有子文件夹)中选择,语法是
"文件夹名",双引号不能省略。 - 单个文件:查询指定的单个文件,语法是:
文件路径/文件名字.md - 链接:可以查询链接,指向文件的链接,也可以选择来自文件的所有链接
- 要获取链接到
[[笔记名]]的所有页面,请使用FROM [[笔记名]] - 要获取从
[[笔记名]]链接的所有页面(即该文件中的所有链接),请使用FROM outgoing([[笔记名]])
- 要获取链接到
在 From 里过滤 filters
[!warnning] 注意
很多时候,我们需要进行一定的筛选过滤
- 比如同时要查文件夹下的某个标签,
- 或者不想要某个标签。
- 或者不想要某个文件。
[!danger] 筛选条件
我们可以使用几个条件进行筛选,非常容易理解。
注意英文符号,前后有一个空格
–and: 和,同时满足
–or: 或,任选其一
–-: 减,排除掉这个条件
示例:
# 查询 文件夹名1 下同时有 #标签名 的数据
from "文件夹名1" and #标签名
# 查询 文件夹名1 和 文件夹名2 ,同时查两个文件夹
from "文件夹名1" and "文件夹2"
# 查询 #标签名1 或者 #标签名1 ,任选其中一个
from #标签名1 or #标签名2
# 查询 文件:文件名1 或者 文件:文件名2 中的内容,任选其一
from [[文件名1]] or [[文件名2]]
# 查询 文件夹:文件夹名1,并且排除其中带有标签 #标签名1 的文件
from "文件夹名1" - #标签名1
# 查询 文件夹:文件夹名1,并且排除其中的文件:文件名1
from "文件夹名1" - [[文件名1]]
# 查询 文件夹,并排除另一个文件夹 2024-04-29新增
FROM "tasks" AND -"tasks/Archived" FROM "tasks" AND !"tasks/Archived"
View 数据呈现的样式
查询结果可以有四种样式:
- TABLE: 表格样式,传统的视图类型;每个数据点有一行,有几列的字段数据.
- LIST: 列表样式,匹配查询的页面的列表。你可以为每个页面输出一个单一的关联值.
- TASK: 任务列表,页面符合给定查询的任务列表.
- CALENDAR: 一个日历视图,通过其相关日期上的一个点来显示每一个命中率。
Where 过滤器 – 查函数
作为参考SQL的DQL查询,也会使用SQL查询的概念。where 就是一个典型的条件语句。他的作用就是过滤掉符合你要求条件的内容。
[!info] 提示
– 所以你理解为一个过滤器,你指定条件,他帮你过滤内容
– where 后面跟上条件,这里可以使用dataview提供的大量内置函数来实现效果。[!info] 注意
– 下面放一些常用的函数,其实常用的就这么些,稍微举几个例子,大家也就清楚了。
– 其他的函数,参考执行就可以。
– 复制这里贴出的代码,严格注意格式,符号都是英文
contains() 包含函数
- 对于对象,检查该对象是否有具有给定名称的键
- 对于列表,检查是否有任何数组元素等于给定值
- 对于字符串,检查给定值是否为子字符串
contains(file.name, "咖啡豆") = true
# 检查对象 file.name ,包含“咖啡豆”,就返回结果为 真
实战1:where带contains()
- contains()语句
where contains(file.name, "咖啡豆") = true
# 检查对象 file.name ,包含“咖啡豆”,就返回结果为 真
# 1. file.name 是dataview的隐式字段,前面讲到过,还有很多可以拿来查询
# 2. "咖啡豆" 是查询的文字,必须用英文的双引""号包裹
- 完整查询语句table
table
file.mtime as "修改时间"
from ""
where contains(file.name, "咖啡豆") = true
sort file.name desc
# 用表格显示结果,表头是文件修改时间。
# 从所有的文件里查询
# 过滤条件是:文件名中包含咖啡豆的结果
# 按照文件名排序
# 1. file.name 是dataview的隐式字段,前面讲到过,还有很多可以拿来查询
# 2. "咖啡豆" 是查询的文字,必须用英文的双引""号包裹
```dataview
list
from ""
where contains(file.name,"索引") = false
sort file.ctime desc
```
</code></pre>
<code>file.name</code>、<code>file.tags</code>、<code>file.path</code>、<code>file.folder</code> 等等众多的隐式字段都可以使用。但是注意有些字段是时间格式,不能错误。
<blockquote>
<strong>参考文档</strong>:<a class="wp-editor-md-post-content-link" href="https://obsidian.vip/zh/dataview/dataview-advanced-a.html#%E9%9A%90%E5%BC%8F%E5%AD%97%E6%AE%B5">隐式字段</a>
</blockquote>
<h3>data(any) 日期函数</h3>
从提供的字符串、日期或链接对象中分析日期(如果可能),否则返回nul
<pre><code class="language-sql line-numbers">date("2020-04-18")
# 日期对象代表 2020年4月18日
date([[2021-04-16]])
# 给定页面的日期对象,参考file.day
</code></pre>
<h3>dur(any) 从字符串解析时间</h3>
从提供的字符串或持续时间分析<strong>持续时间</strong>,失败时返回null
<pre><code class="language-sql line-numbers">dur(8 minutes)
# 8分钟
dur("8 minutes, 4 seconds")
# 8分4秒
dur(dur(8 minutes))
# dur(8 minutes) = <8 minutes>
</code></pre>
<h3>实战2:where带2个函数查询</h3>
<pre><code class="line-numbers">list
from ""
WHERE file.mtime >= date(today) - dur(7 day)
sort file.mtime desc
</code></pre>
<pre><code class="line-numbers">table without id
file.link as 文件名,
file.folder as "文件夹",
file.mtime as 修改时间
from "" and -#obsidian
WHERE file.mtime >= date(today) - dur(7 day)
sort file.mtime desc
limit 20
</code></pre>
<h2>Where 过滤器 - 查自定义字段</h2>
我们也可以查询自定义字段,也就是前文所讲的 <code>frontmatter</code> 和 <code>inline 内联字段</code>
<blockquote>
参考资料:[[Dataview进阶 —— 基础字段]]
</blockquote>
<h2>Sort 排序</h2>
按一个或多个字段对所有结果进行排序。
<pre><code class="language-sql line-numbers">SORT date [ASCENDING/DESCENDING/ASC/DESC]
</code></pre>
<pre><code class="line-numbers">sort file.mtime desc
</code></pre>
<blockquote>
[!tips] 排序方式
- ASC:升序
- DESC:降序
</blockquote>
<h2>FLATTEN 数据扁平化</h2>
扁平化是很拗口的一个说法,其实就是将一组数据变成多行数据,每个数据一行,展开方便阅读而已。
<blockquote>
[!warnning] 概念
打个比方:一个Excel的数据,有多列,现在按照某一列的数据,展示出来,展示的结果是一个数据占一行
[!success] 举例
展平每个书籍注释中的 <code>作者</code> 字段,为每个作者放一行
</blockquote>
什么时候使用?
<pre><code class="line-numbers">```dataview
TABLE 作者
FROM #书籍
FLATTEN 作者
```
| 书名 | 作者 | 出版日期 | 出版社 | 价格 |
|-----------------------|--------------|--------------|------------|-----------|
| 阳光下的快乐笔记 | 欢快小编 | 2023-03-15 | 欢乐出版社 | $20.00 |
| 欢笑的故事集 | 笑声大师 | 2022-11-10 | 快乐出版社 | $18.50 |
| 快乐的文字游戏 | 文字欢喜人 | 2023-05-20 | 欢乐文化 | $22.99 |
| 欢快心情的诗歌 | 欢歌诗人 | 2022-09-08 | 欢歌出版 | $15.75 |
| 欢跳的小说世界 | 欢乐作家 | 2023-01-30 | 欢跳出版 | $24.99 |
查询结果示例:
| 文件名称 | 作者 |
|---|---|
| 阳光下的快乐笔记 | 欢快小编 |
| 欢笑的故事集 | 笑声大师 |
| 快乐的文字游戏 | 文字欢喜人 |
| 欢快心情的诗歌 | 欢歌诗人 |
| 欢跳的小说世界 | 欢乐作家 |
GROUP BY数据分组
这是一个很有意思的命令,当你查询出来的数据想按照一定的要求分组显示。就可以使用。
比如在 list 视图下面,
- 将结果按照不同的日期分组显示
- 将结果按照不同的文件夹展示
- 将结果按照不同的文件路径展示
- 其他的参数
file.name文件名称file.cday文件创建日期file.mday文件修改日期
list视图/按照文件夹分组
list rows.file.link
from "Longform"
where file.name != "Index"
GROUP BY file.folder
- 按照 list 展示,并加上参数 row.file.link 文件链接
- 从 Longform 文件夹查询
- where 限制条件:不允许文件名中包含 Index 的文件
- 分组展示,按照 file.folder 文件夹
[!success] 注意:这里有个小技巧
– list 视图,我们追加了显示,在原有显示的基础上增加了 row.file.link,这一句会增加一个文件的链接。
– 因为我们使用了GROUP BY分组之后,会失去文本的链接,所以需要使用上面的语法增加链接。对于 [[Dataview进阶 —— 综合技巧]] 的方法,可以看这篇文章
limit 限制显示数量
当你查询的数据过多的时候,可能不想显示太多的内容。那么我们可以控制显示数据的数量,比如只显示10个。语法简单,不多赘述
limit 10