- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
一、语法结构
DQL 查询语言的语法定义如下:
TABLE or LIST or TASK or CALENDER [WITHOUT ID] <field> or <field AS alias>
FROM <source>
WHERE <clause>
SORT field1 [ASCENDING/DESCENDING/ASC/DESC], ..., fieldN [ASC/DESC]
GROUP BY <value> [AS <name>]
LIMIT <value>
FLATTEN <value> [AS <name>]
注意:这个语法定义非官方提供,在文章中仅为了方便描述。除了查询类型和 FROM 语句位置固定外,其它语句统称数据命令(Data Command),可以多次使用,位置不固定。
1. 查询类型 TABLE/LIST/TASK/CALENDAR
官方提供了 4 种类型:
TABLE: 以表格方式显示结果。LIST: 以列表方式显示结果。TASK: 显示满足过滤条件的交互式任务(对过滤结果的操作状态会同步到原始文档中对应的任务)。CALENDAR:在日历中对应的日期中标记点。
2. 排除默认值 WITHOUT ID
<WITHOUT ID> 用于 LIST 类型中,表示在查询的结果中不显示文件名或者分组名。

<WITHOUT ID> 用于 TABLE 类型中,表示在查询的结果中不显示第一列链接文件名。
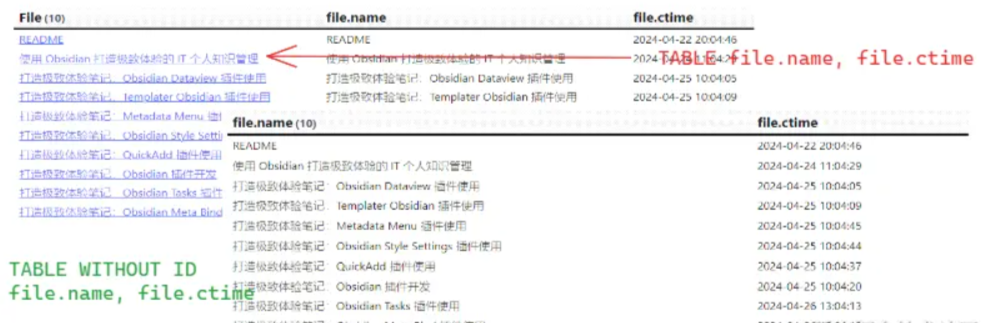
如果用于分组后的数据,则不显示分组名。

3. FROM 语句
<FROM> 语句表示查询来源,如果不指定则查询当前 Obsidian 仓库中的所有文档。
如果指定在当前文档中进行查询,可以将 <FROM> 来源指定为文档的路径:
TABLE file.name, file.ctime
FROM "博客/Obsidian/打造极致体验笔记:Obsidian Dataview 插件使用"
上面我们从指定的文档获取数据源,当然也可以指定目录,例如:FROM "博客/Obsidian",此外,也可以指定标签,再结合运算符来过滤数据源,例如:FROM #博客 AND "Go",结果为博客中 Go 目录下的所有文件。
除了从标签、文档和目录中获取内容外,还可以从 Obsidian 的双向链接中获取数据源,这里我们简单的补充一下链接的知识。
在文档中插入的 URL 图片地址,网页 URL 地址,我们称之为外部链接。如果在 Obsidian 文档中想要引用其它文档,或者其文档中的标题,部分段落,我们需要创建内部链接。在 Obsidian 中我们通常将内部链接称作双链或者双向链接,然后在 Obsidian 环境中我们使用链接(Link)指代内部链接,如果有特殊情况会单独说明。
在文档中创建链接的语法为 [[文档名称]],当我们输入前两个中括号后,Obsidian 界面中会弹出文档选择下拉列表,然后自动插入文档名称和补全后面的两个中括号。一个文档内部可能会引用多个外部文档的链接,同时文档也会被别的文档引用为链接,这样就行成了一个双向的链接。我们将当前文档引入的链接称之为出链(Outgoing links),如果有其它文档引用了当前文档,则将其它文档称之为外链(Backlinks)。
在引入其它文档内容时我们可以选择指向整个文档,也可以引用文档标题,进一步还可以引用某个段落(块),此外还可以对引用的内容指定别名。下面是 4 种链接引用方式举例,其中 x 用来指代任意符合链接规范的文本,在 Obsidian 中输入 [[ 后全是可视化操作选择,例如在选择文档后,在文档后输入 | 会加载文档内容让你选择要引用的段落。
- 链接到文档(
[[x]]):[[打造极致体验笔记:Obsidian Dataview 插件使用]] - 链接到文档中的标题(
[[x#x]]):[[打造极致体验笔记:Obsidian Dataview 插件使用#FROM语句]] - 链接到文档中的段落(
[x#^x]):[[打造极致体验笔记:Obsidian Dataview 插件使用#^065c03]] - 链接到文档中的段落并使用别名 (
[x#^x|x]):[[打造极致体验笔记:Obsidian Dataview 插件使用#^065c03|这是别名,会替换原文档名]]
然后我们来看一下如何查询外链和出链。通常在 FROM [[x]] 查询的结果为外链,如果要查询出链则需要调用 outgoing() 函数:
LIST file.name
FROM outgoing([[打造极致体验笔记:Obsidian Dataview 插件使用]])
4. WHERE 语句
WHERE 语句用于过滤数据,这里我们再次实现在 <FROM> 语句中查询当前文档的操作。
TABLE file.name, file.ctime
WHERE file = this.file
5. SORT 语句
SORT 语句用于对结果进行排序,排序方式有升序 (ASC | ASCENDING) 和降序(DESC | DESCENDING)二种方式,如果不指定则默认按升序排序。下面的查询结果以创建时间升序显示。
TABLE file.name, file.ctime
SORT file.ctime ASC
6. GROUP BY 语句
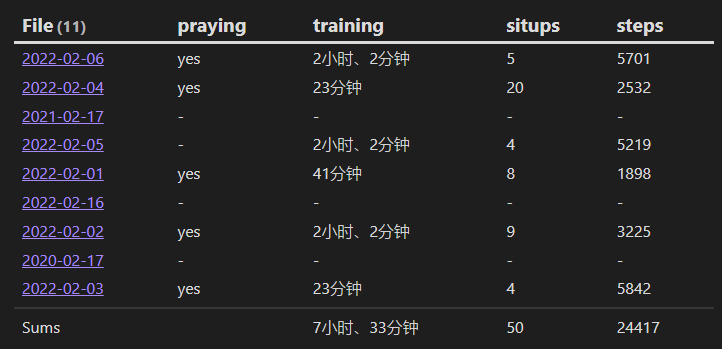
GROUP BY 语句用于对查询的结果进行分组显示,需要注意的是它的用法,如果我们在上面 SORT 语句示例中添加按 file.cday 分组的话,除了加上 GROUP BY file.cday 外,还需要将 file.name, file.ctime 修改成 rows.file.name, rows.file.ctime,因为我们需要从分组后的结果中获取文档信息,这个匹配的结果存储在属性 rows 数组中。这里我们不需要自己来处理索引,如果你想要获取分组结果数组中第 3 项的结果,可以直接这样写 rows[2].file.name。
TABLE WITHOUT ID rows.file.name, rows.file.ctime
SORT file.ctime ASC // 使用分组时,默认会对数据进行排序,这里可以不写。
GROUP BY file.cday
结果:
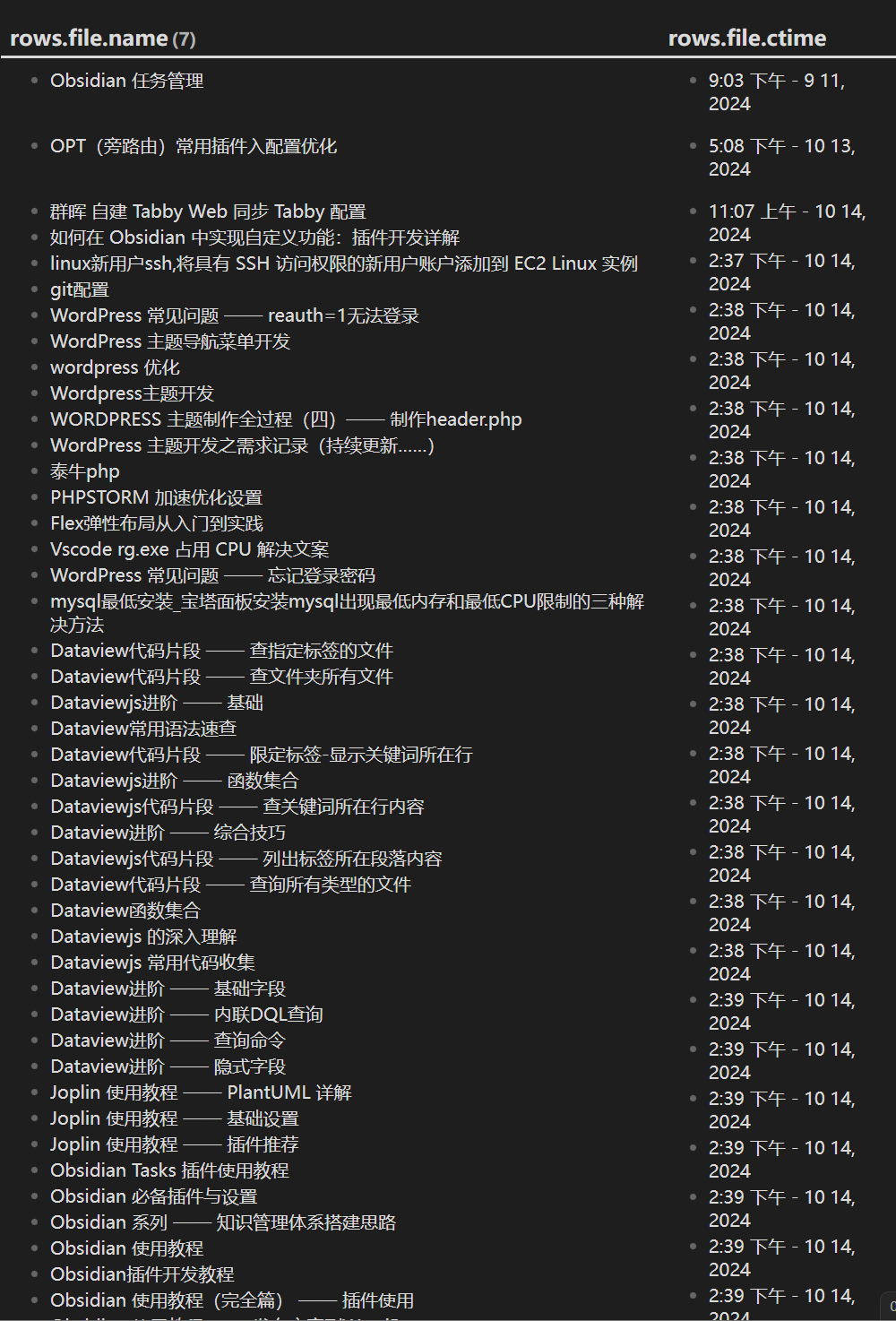
如果我们相要获取第 3 个分组中第 3 项数据,可以写成 TABLE WITHOUT ID rows[2].file.name, rows[2].file.ctime

7. FLATTEN 语句
FLATTEN 语句的作用是展开(扁平)数组,举个例子:[1, [2, [3, 4], 5]] 展开后:[1, 2, 3, 4, 5],但是这里并不一定恰当,因为在 DataView 中我们区分查询类型,比如说多级嵌套的任务就比较贴合前面说的展开数组的情况。现在我们就利用前面章节中的任务数据来举例。
TABLE WITHOUT ID T.text as "任务名称"
FLATTEN file.tasks as T
WHERE T.completed AND file = this.file
结果:

FLATTEN 语句的所有使用都需要结合 TABLE 查询类型来输出结果。
现在再来演示另一种使用 FLATTEN 的场景,这刚好与 GROUP BY 语句结果相反。现在有一个目录 books 放置了很多书籍,每一个文档代表一本书,文档中设置 genres 属性来作为分类(Children, Romance, Magic 等等),当我们使用 TABLE genres 查询时,结果是每个分类占据表格的一行,而默认文档链接会根据分类数量自动合并行,现在想要相同行不合并显示,这时就需要使用 FLATTEN genres 来实现。
TABLE genres
FROM "10 Example Data/books"
FLATTEN genres

接着上面书籍的案例,现在想要根据阅读页数(pageRead)和总页数(totalPages)来计算出阅读进度,并且过滤掉进度少于 50% 的书籍,这里我们可以使用 FLATTEN 来声明一个新的字段 progress 来实现:
TABLE pagesRead, totalPages, percentage
FROM "10 Example Data/books"
FLATTEN round((pagesRead / totalPages) * 100) AS progress
WHERE progress > 50
FLATTEN progress + "%" AS percentage
结果:

8. LIMIT 语句
LIMIT 语句的作用很简单,就是限制结果的数量,例如将结果限制为最多 5 个值:LIMIT 5。
二、查询类型
因为上面基体将 DataView 提供的查询类型介绍了一遍,这里就不再细说,只补充部分内容。
- 对于
LIST和TASK类型如果不指定FROM或WHERE条件则获取整个 Obsidian 仓库中所有列表或任务。 LIST后面提供额外的信息来自定义输出结果,例如:LIST "File Path: " + file.folder + " _(created: " + file.cday + ")_"。- 使用
GROUP BY分组后,我们获取分组后的数据需要从rows属性中读取。 WITHOUT ID只适用于LIST和TABLE类型。
三、表达式
在 DataView 中除了查询类型和数据命令外,其它数据统称表达式。
如果会 JavaScript 语言,那么对于数字(Number)、布尔值(Boolean)、字符串(String)、数组(Array)和对象(Object)的概念不会感到陌生,DataView 进一步提供了日期和时间(Date)、持续时间(Duration)和链接(Link)三种类型,下面举例说明:
1,0.5,-5:数字true,false:布尔值"Lorem ...":文本,JavaScript 中为字符串date(2024-04-28):日期值dur(1 day),dur(3 minutes):持续时间[[Link]],[[Link#xx]],[[Link#^xx]][[Link#xx|xx]]:链接[1, 2, 3]:列表,JavaScript 中为数组{a: 1, b: 2, c: [1, 2, 3]}:对象
在 JavaScript 中不提供函数名称的函数称之为匿名函数,比如在函数中返回一个函数:function foo() {return function() {console.log("Hello Dataview")}},在使用数组过滤时我们通常这样写:arr.filter(function(item) {return item.xx > 0}),进一步我们可以简写为 arr.filter(item => item.xx > 0),这里的写法称之为箭头函数,它与普通函数的区别就不作说明了,对应于 DataView 中称之为 Lambdas 表达式,作用是一样的,唯一需要注意的是变量名必需加括号,例如 (item) => item.xx > 0。
在 DataView 中读取变量值或者属性值,调用函数语法和 JavaScript 中是一样的,例如通过对象名+属性名(obj.prop),对象名+计算属性(obj[item_${index}]),函数调用 (f(a, b))。
对于数字最常见就是四则运算:加(+)、减(-)、乘(*)和除(/),然后再加一个除余(%)运算,比较运算则为大于(>),小于(<),等于(=,注意在 JavaScript 中是区分 \== 和 \=== 的),不等于(!= ),大于等于(>=)和小于等于(<=)。对于文本可使用加号(+)来拼接字符,使用 文本 * 数字 可重复文本指定次数,例如:"a" * 5 结果为:"aaaaa"。
最后对于链接的文件中的属性我们直接使用 [[Link]].value 读取即可。
1. 日期类型(Dates)
日期类型的值格式需要满足 Data ISO format 规则,我们通常以 2024-04-29 11:11:23 或者 2024/04/29 11:11:23 的格式来表示日期+时间,这更符合国人的习惯。
DataView 提供了一个 date() 函数来构造一个日期对象,这个函数有 2 种签名:date(any) 和 date(text, format)。
(1)date(any) 使用
需要注意的是传入 date() 函数的日期是可以不加引号的,例如:date(2024-04-29),对于有具体时间的日期我们不能以:date(2024-04-29 11:20:20) 这种形式传入,正确的姿势是:date(2024-04-29T11:20:20),这里的 T 为日期分隔符。DataView 为 date() 函数预定义了很多具有描述性质的常量参数,例如:date(now) 表示当前日期和时间,具体如下:
today:表示当前日期now:表示当前日期+时间tomorrow:表示明天的日期yesterday:表示昨天的日期sow/eow:表示当前周的开始日期和结束日期som/eom:表示当前月的开始日期和结束日期soy/eoy:表示当前年份的开始日期和结束日期
注:
so为start of的缩写,eo为end of的缩写。
下面使用内联 DQL 查询来演示:
日期:: 2024-04-29
时间:: 2024/04/29 11:01:20
`= this.日期` %% 2024-04-29 %%
`= this.时间` %% 2024/04/29 11:01:20 %%
现在时间:`= date(now)` %% 现在时间:2024-04-29 13:04:05 %%
指定日期1:`= date(2024-04-29)` %% 2024-04-29 %%
指定日期2:`= date("2020-04-18")` %% 2024-04-18 %%
指定日期3:`= date([[2024-04-23]])` %% 2024-04-23 %%
指定时间4:`= date(2024-04-29T11:20:20)` %% 2024-04-29 11:04:20 %%
指定日期5:`= date([[Place|2021-04]])` %% 结果 %%
昨天:`= date(yesterday)`,明天:`= date(tomorrow)` %% 昨天:2024-04-28,明天:2024-04-30 %%
周开始与结束日期:`= date(sow)` / `= date(eow)` %% 周开始与结束日期:2024-04-29 / 2024-05-05 11:05:59 %%
月开始与结束日期:`= date(som)` / `= date(eom)` %% 2024-04-01 / 2024-04-30 11:04:59 %%
年开始与结束日期:`= date(soy)` / `= date(eoy)` %%0 2024-01-01 / 2024-12-31 11:12:59 %%
注:
%% %%部分为 Obsidian 中的注释
上面的代码中我们始终以 xxxx-xx-xx 或 xxxx-xx-xxTxx:xx:xx 的格式传入 date() 函数中,这也是唯一合法的格式,其它例如:date(2024/04/29), date(Mon Apr 29 2024 14:45:46 GMT+0800 (中国标准时间)) 以及 data(1714366864889) 都是不合法的。如果相要使用这些格式作为输入就需要使用第二种形式了。此外,我们在前面【快速入门】中有提过修改 Obsidian 日期输出的默认格式,如果没有修改可能得到的结果日期为 MMMM dd, yyyy 格式,时间为 h:mm a - MMMM dd, yyy 格式。
(2)date(text, format)使用
date() 函数的这种使用方式设计是有点让人产生歧义,初看以为是一种类似日期 format 类似的作用,实则不是。它的第 1 个参数必须是文本,不可传入变量,然后第 2 个参数你以为可以使用任何满足 Luxon 时间库格式化的字符,那就理解错了,它真正的作用是为了解决上面我们说的除唯一合法格式以外的输入,请看下面的示例:
上面的代码中我们始终以 xxxx-xx-xx 或 xxxx-xx-xxTxx:xx:xx 的格式传入 date() 函数中,这也是唯一合法的格式,其它例如:date(2024/04/29), date(Mon Apr 29 2024 14:45:46 GMT+0800 (中国标准时间)) 以及 data(1714366864889) 都是不合法的。如果相要使用这些格式作为输入就需要使用第二种形式了。此外,我们在前面【快速入门】中有提过修改 Obsidian 日期输出的默认格式,如果没有修改可能得到的结果日期为 MMMM dd, yyyy 格式,时间为 h:mm a - MMMM dd, yyy 格式。
(3)date(text, format) 使用
date() 函数的这种使用方式设计是有点让人产生歧义,初看以为是一种类似日期 format 类似的作用,实则不是。它的第 1 个参数必须是文本,不可传入变量,然后第 2 个参数你以为可以使用任何满足 Luxon 时间库格式化的字符,那就理解错了,它真正的作用是为了解决上面我们说的除唯一合法格式以外的输入,请看下面的示例:
日期1:`= date("12/31/2022 12:12:12", "MM/dd/yyyy HH:mm:s")` %% 2022-12-31 12:12:12 %%
日期2:`= date("2023/10/12", "yyyy/MM/dd")` %% 2023/10/12 %%
日期3:`= date("210313", "yyMMdd")` %% 2021/03/13 %%
时间缀(毫秒):`= date("1714366864889", "x")` %% 2024-04-29 01:04:04 %%
时间缀(秒):`= date("1407287224", "X")` %% 2014-08-06 09:08:04 %%
日期格式化有专门的函数 dateformat(date|datetime, string) 来处理
2. 持续时间类型(Durations)
要表示持续时间类型需要调用 dur(any) 函数传入描述字面量,可以描述年、月、日、时、分、秒和周,例如:dur(1 h) 根据当前的语言环境会解析成:1小时。
s/sec/secs/second/seconds:表示x秒钟。m/min/mins/minute/minutes:表示x分钟。h/hr/hrs/hour/hours:表示x小时。d/day/days:表示x天。w/wk/wks/week/weeks:表示x周。mo/month/months:表示x个月。yr/yrs/year/years:表示x年。
下面是一些基础示例:
年:`= dur(5 yr)` %% 5年 %%
月:`= dur(5 mo)` %% 5个月 %%
日:`= dur(5 d)` %% 5天 %%
小时:`= dur(5 h)` %% 5小时 %%
分钟:`= dur(5 m)` %% 5分钟 %%
秒数:`= dur(5 s)` %% 5秒钟 %%
周:`= dur(3 w)` %% 3周 %%
接下来看一下复杂的组合示例,我们会发现 Dataview 会自动推算出合适的表达:
100天:`= dur(100 d)` %% 3个月、2周、2天 %%
36个月:`= dur(36 mo)` %% 3年 %%
50周:`= dur(50 w)` %% 1年、2周 %%
160分钟:`= dur(160 m)` %% 2小时、40分钟 %%
1500秒:`= dur(1500 s)` %% 25分钟 %%
100分钟12秒:`= dur(100 m, 12 s)` %% 1小时、40分钟、12秒钟 %%
3年5个月12天:`= dur(3 yr, 5 mo, 12 d)` %% 3年、5个月、1周、5天 %%
除了单独使用外,更多的场景是结合 date() 函数一起使用:
过去5天:`= date(now) - dur(5 d)` %% 2024-04-24 17:04:02 %%
过去2周:`= date(now) - dur(2 w)` %% 2024-04-15 17:04:02 %%
明天:`= date(now) + dur(1 d)` %% 2024-04-30 17:04:02 %%
往后3年:`= date(now) + dur(3 yr)` %% 2027-04-29 17:04:02 %%
十秒前:`= date(now) - dur(10 m)` %% 2024-04-29 16:04:02 %%
四、内置函数
DataView 提供了大量的函数来提高处理文档的效率,这里的函数官方文档将其分为:构造函数、数字计算函数、对象,数组和字符串操作函数以及工具(辅助)函数。
1. 构造函数
构造函数用于构建对象的实例,这里的对象可以是普通 JavaScript 中的对象、字符串和数字,也可以是 DataView 中的列表、日期、持续时间和链接等。接下来我们通过实例来辅助理解每个函数,就不再一一列举讲解了。
对于函数 date(any),date(text, format) 以及 dur(any) 我们在章节【表达式】中有详细介绍,请自行回顾。
下面我们举例来说明 object(key1, value1, ...), list(value1, value2, ...), number(string) 和 string(any) 的使用,需要注意的是通过内联 DQL 查询后显示结果,对象显示为:key: key2: key3: value 的形式,而列表不分是否嵌套统一显示成 value, value, ... 的形式。
普通对象:`= object("a", 123)` %% a: 123 %%
获取对象的值1:`= object("a", 123).a` %% 123 %%
获取对象的值2:`= extract(object("a", 123), "a")` %% a: 123 %%
嵌套对象:`= object("a", object("b", object("c", 123)))` %% a: b: c: 123 %%
普通列表:`= list(1, 2, 3)` %% 1, 2, 3 %%
嵌套列表:`= list(list(1, 2, 3), list(4, 5, 6))` %% 1, 2, 3, 4, 5, 6 %%
对象列表:`= list(object("a", 1), object("a", 2))` %% a: 1, a: 2 %%
普通数字:`= number(123)` %% 123 %%
负数:`= number(-123)` %% -123 %%
小数:`= number(1.34)` %% 1.34 %%
字符串中包含数字1:`= number("12hhh34")` %% 12 %%
字符串中包含数字2:`= number("hhh34wer123")` %% 34 %%
字符串中包含数字3:`= number("wer123")` %% 123 %%
非数字:`= number("nonnum")` %% - %%
普通字符串:`= string("hello world")` %% hello world %%
数字字符串:`= string(123)` %% 123 %%
日期:`= string(dur(3 h))` %% 3小时 %%
上面的示例我们使用内联 DQL 查询,对于一个普通的对象如何在 DQL 显示呢?这里我们需要借助 FLATTEN 语句来实现:
TABLE WITHOUT ID T.name AS 姓名, T.age AS 年龄
FLATTEN object("name", "jenemy", "age", 33) AS T
WHERE file = this.file
结果:

如果是列表对象,写成 FLATTEN list(object("name", "jenemy", "age", 33), object("name", "lulu", "age", 26)) AS T 就可以了。
接下来我们来看一下通过 link(path, [display]) 函数如何来创建链接,有些什么需要注意的点。
假如现在我们的文档目录树如下:
|- Obsidian
| |- 笔记一.md
| |- 笔记二.md
| └─ Dataview
| |- 笔记一.md
| └─ 笔记二.md
|- 笔记一.md
|- 笔记二.md
└─ 笔记三.md
现在我们在 Obsidian/Dataview/笔记一.md 中使用 linK("笔记二") 引用笔记二。上面的目录我最后一次编辑停留在了最外层的笔记二文档中,当我们点击链接时直接跳到了最外层和笔记二文档。然后我们再次打开同级的笔记二编辑,发现还是跳转最外面的文档二。接下来我们在 Obsidian 这一级目录的笔记一中创建同样的链接,操作后发现还是跳到了最外层的文档二。然后我们最后一次重新创建目录和文档,最后一个创建的文档二不在最外层,再次操作后还是同样的效果,删除最外面的文档后才跳转到同级的文档二。总结一下:link() 函数会从最外层寻找链接的文档,然后才是同级目录下的文档。
经过上面的实验我们需要注意的是在指定链接时一定要加是路径,如果在文档内引用了多个同名的文档,最好使用别名来标识。下面是一些使用示例:
`= link("笔记二)"` %% 根目录下的笔记二 %%
`= link("/笔记二)"` %% 根目录下的笔记二 %%
`= link("./笔记二")` %% 同级目录笔记二 %%
`= link("Obsidian/笔记二")` %% Obsidian 目录下的笔记二 %%
`= link("./笔记二", "别名")` %% 使用别名 %%
然后我们再来看一下如何使用 embed(link, [embed?]) 嵌入图片和 elink(url, [display]) 创建外部链接。
`= embed(link("bg_1.jpg"))` %% 图片位于附件默认存放路径中 %%
`= elink("www.baidu.com")` %% 创建百度外部链接 %%
`= elink("www.google.com", "谷歌搜索")` %% 显示指定的别名,而非地址 %%
最后我们来看一下如何判断数据类型,,这里我们使用 typeof(any) 函数来判断:
`= typeof(12)` %% "number" %%
`= typeof("abc")` %% "string" %%
`= typeof(link("笔记二"))` %% "link" %%
`= typeof(list(1, 3, 4))` %% "array" %%
`= typeof([1, 3, 4])` %% "array" %%
`= typeof(object("a", 1))` %% "object" %%
`= typeof({ a: 1 })` %% "object" %%
`= typeof(date(now))` %% "date" %%
`= typeof(dur(1 d))` %% "duration" %%
`= typeof(true)` %% "boolean" %%
2. 数字运算
对于数字的操作除了前面章节介绍过的四则运算和求余运算外,比较常见的还有求最大值(max(a, b, ..))、最小值(min(a, b, ..))、求和(sum(array))、向上取整(ceil(number))、向下取整(floor(number))、四舍五入(round(number, [digits]))、平均值(average(array))以及小数位截断(trunc(number))等。
四舍五入:`= round(16.5555)` %% 17 %%
保留2位小数:`= round(16.5555, 2)` %% 16.56 %%
小数点截断:`= trunc(-12.937)` %% -12 %%
向下取整:`= floor(12.937)` %% 12 %%
向上取整:`= ceil(12.937)` %% 13 %%
最小值:`= min(5, 2, 4, 8)` %% 2 %%
最大值:`= max(5, 2, 4, 8)` %% 8 %%
求和:`= sum([1, 2, 3, 5])` %% 11 %%
求平均值:`= average([1, 2, 4, 5])` %% 3 %%
数字数组乘积:`= product([1, 2, 3, 5])` %% 30 %%
累加:`= reduce([1, 3, 5], "+")` %% 9 %%
累除:`= reduce([200, 10, 5], "/")` %% 4 %%
字符重复:`= reduce(["a", 3], "*")` %% aaa %%
在使用 average() 时如果传入空数组,结果将为 null,在页面中渲染为 -,如果明确知道有 null 值,可以使用 nonnull(array) 函数来移除空值再计算:average(nonnull([null, 1, 3, 5])),同样适合于接收数组参数的 sum() 和 product() 函数。
minby(array, function) 和 maxby(array, function) 用于根据指定的函数来返回最小值和最大值。
最小值:`= minby([1, 3, 5], (v) => v)` %% 1 %%
将正整数按负数进行比较获得的最小值:`= minby([1, 2, 3], (v) => 0 - v)` %% 3 %%
对一组单词返回最长的词汇:`= maxby(["Compute", "the", "maximum", "value"], (v) => length(v))` %% maximum %%
3. 对象、数组和字符串操作
这里的函数分为对象操作、数组操作(列表(List)操作其实也是数组操作)和字符串操作以及同时作用于多种类型的函数。对于数组的操作有一定编程经验的读者对于像映射(map(array, func))、过滤( filter(array, predicate))、合并(join(array, [delimiter]))、数组展开(flat(array, [depth]))、数组切片(slice(array, [start, [end]]))以及排序(sort(list))和逆转(reverse(list))不会陌生,然后这里获取数组长度没有 length 属性,需要通过 length(object|array) 函数来获取。
下面通过一些实际的例子来理解这些数组函数的用法:
`= map(["Ctrl", "Shift", "Alt"], (v) => "<kbd>" + v + "</kbd>")` %% Ctrl, Shift, Alt %%
`= filter([true, false, true, true, false], (v) => !v)` %% false, false %%
`= join(["a", "b", "c"], ",")` %% a,b,c %%
`= flat([1, [2, 3], [4, 5, [6, 7]], 8])` %% 1, 2, 3, 4, 5, 6, 7, 8 %%
`= slice([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 1, 3)` %% 1, 2 %%
`= sort(["foo", "bar", "baz"])` %% bar, baz, foo %%
`= reverse([1, 2, 3, 4, 5])` %% 5, 4, 3, 2, 1 %%
`= length([1, 2, 3])` %% 3 %%
对于函数 flat(array, [depth]),默认情况下只展开第一级数组(depth = 1),下面我们在 DQL 查询中看一下一个 4 层数组 [1, [2, [3, [4, [5, 6]]]]] 分别使用默认和 depth = 3 的结果:
TABLE WITHOUT ID T
FLATTEN flat([1, [2, [3, [4, [5, 6]]]]], 1) as T
WHERE file = this.file
结果:

需要注意的是 slice(array, [start, [end]]) 函数所返回的切片数组是不包含 end 所在索引的值。start 和 end 都是可选值,意味着可以不传值就直接返回一新数组,如果是传一个值则返回 start 所在位置的索引到数组长度的值,如果 2 个值都传则返回位于 [start, end) 前开后闭索引区间的值。如果我们指定的索引值大于数组的长度会抛出异常。最后还可以输入负数作为 start 和 end 的值,结果取的是负数值加上数组长度后的索引值(如果是负数值我们倒着数索引和加上数组长度是一样的结果)。
sort(list) 函数对于数字按从小到大排序,即升序排序,sort([1, 3, 23, 8, 2]) 结果为 1, 2, 3, 8, 23。对于字符串按字母顺序排序,按同一个字母的小写字母,大写字母的顺序排序,如果第一个字母相同则按同样的规则以次排序,sort(["A", "B", "c", "d", "a", "E"]) 结果为:a, A, B, c, d, E,而非 a, c, d, A, B, E。
下面我们介绍一个重要的函数 contains(object|list|string, value) 和其变种,这个函数的作用是用于判断在对象、数组和字符串中是否包含给定的字符(串),对于对象我们关注的是是否包含某个键值,数组则是否包含某个数组项值,字符串则是判断是否包含特定的字符(串)。
`= contains(object("a", 1, "b", 2), "a")` %% true %%
当前文件名是否包含日期:`= contains(this.file, "day")` %% false %%
`= contains(list(1, 2, 3), 3)` %% true %%
`= contains([], 3)` %% false %%
`= contains("abcdefg", "bc")` %% true %%
`= contains("abcdefg", "BC")` %% false %%
从上面的示例中我们会发现 contains() 函数是区分大小写的,如果想要忽略大小写,则可以使用 icontains(object|list|string, value) 函数。
注:
icontains()函数中的字母i是 Ignore Case 的意思。
下面看一下使用 contains() 和 icontains() 函数的一个例子:
`= contains(["acb", "bcd", "efg", "egk"], "cb")` %% true %%
`= icontains(["abc", "Abc", "ABC", "abC"], "Bc")` %% true %%
注意到在数组中只是包含了 value 值,但不是相同,因此在需要判断字符串确切相等时,还需要使用另外一个函数:econtains(object|list|string, value),它能够判断是否包含完整的 value 值。
继续看下面一个 icontains() 函数的例子:
`= icontains(["foo", "bar", "baz"], "bA")` %% true %%
这个例子中,如果相要在忽略大小写的情况下来判断数组项是否包含某个单词,而不是部分字符时,icontains() 函数就显得捉襟见肘了,这便引入了最后一个和 contains 相关的函数 containsword(list|string, value),这个函数不作用于对象,因为根据部分字符去获取一个对象的键值没有意义。
`= containsword("foo, bar, baz, ba", "bA")` %% true %%
`= containsword(["foo", "bar", "baz", "ba"], "bA")` %% false, false, false, true %%
从结果来看,对于字符串返回判断的结果,但是对于列表它会返回列表中每一个列表项是否包含 value 值的一个布尔数组。这个结果数组有什么用呢,其实可以进一步使用 filter() 函数来过滤为 true 的结果,但是这里毫无意义,为什么呢?因为在 DQL 查询语言中提供的所有数组遍历函数并没有在遍历条件函数中提供数组项的索引值,我们无法确切知道是数组中第几个值的结果。
上面已经介绍大部分操作函数了,接下来看几个数组项判断的函数,它们的特点是只需要传入数组,然后返回一个布什值,其中 all(array) 函数要求数组项目中所有值均为 true 的情况下才返回 true,any(array) 函数只要其中有一个值为 true 结果就返回 true 值,最后一个是 none(array) 函数,它其实就是 all() 函数的结果取反。
这 3 个函数均可传入一个判断函数作为第二个参数来根据条件返回结果,下面是使用示例:
`= all(["", 0, null, false])` %% false %%
`= all(1, "a", false)` %% false %%
`= none(["", 0, null, false])` %% true %%
`= any(["", 1, null, false])` %% true %%
`= all([1, 2, 5, 8], (v) => v > 1)` %% false %%
`= any([1, 2, 5, 8], (v) => v % 2 = 0)` %% true %%
`= none([1, 2, 5, 8], (v) => v > 10)` %% true %%
[!Tips] 在 JavaScript 中
null,"",0均代表假值,DQL 查询语言中也使用了同样的规则。
最后还剩下 2 个函数来结束本小节,nonull(array) 函数用于将一个包含 null 值的数组项移除,并返回一个新的数组。length(object|array) 函数用于返回数组的长度,对象的属性数量,因为比较简单就不举例说明了。extract(object, key1, key2, ...) 函数用于获取对象的多个值,请参考前面章节中的使用示例。
4. 字符串操作
这一小节很重要,因为我们在使用 DataView 查询数据时需要作各种判断,这里的很多函数会经常被使用到,除了转换成大写(upper(string))和转换成小写(lower(string))函数比较直观简单外其它函数我们单独来讲解。
regextest / regexmatch / regexreplace / replace 函数
这 4 个函数均使用正则表达式来判断传入的 string 是否匹配 pattern。regextest(pattern, string) 和 regexmatch(pattern, string) 两个函数的使用是一样的,只不过判断的规则不一样,前者只需要部分匹配就返回成功,而后者要求完全匹配规则。
`= regextest("foo", "foo bar baz")` %% true %%
`= regexmatch("foo", "foo bar baz")` %% false %%
下面举一个实际的例子,在 LifeOS for Obsidian (obsidian-life-os.netlify.app) 的示例项目中返回所有未完成的任务时过滤掉目录 Templates 中的模板文件(Daily.md, Monthly.md, Quarterly.md, Weekly.md 和 Yearly.md)中的任务并按文件链接地址分组。
TASK
WHERE !regextest("Templates", file.folder) AND !completed
GROUP BY file.link
上面例子中不能使用 regexmatch() 函数,因为 file.folder 的值是包含路径的,如果使用它就只是匹配了 Templates 这个字符串,达不到预期的结果。
regexreplace(string, pattern, replacement) 函数用于正则替换字符串,例如将日期格式 2024-05-02 替换成 05/02/2024,它同样支持像 JavaScript 的 replace() 函数中那样在 replacement 中使用 $1 来匹配捕获的第一个分组,然后依次类推。
`= regexreplace("2024-05-02", "(\d{4})-(\d{2})-(\d{2})", "$2/$3/$1")` %% 05/02/2024 %%
replace(string, pattern, replacement) 函数虽然函数签名同 regexreplace() 函数,但是只能用于普通的广西替换,下面是一个对比的例子:
`= regexreplace("从 2024-05-02 至 2024-05-03", "(\d{4})-(\d{2})-(\d{2})", "$2/$3/$1")` %% 从 05/02/2024 至 05/03/2024 %%
`= replace("从 2024-05-02 至 2024-05-03", "(\d{4})-(\d{2})-(\d{2})", "$2/$3/$1")` %% 从 2024-05-02 至 2024-05-03 %%
`= regexreplace("foo bar baz, and bar again", "bar", "BAR")` %% foo BAR baz, and BAR again %%
`= replace("foo bar baz, and bar again", "bar", "BAR")` %% foo BAR baz, and BAR again %%
`= regexreplace("foo123foo456foo", "\d+", "")` %% foofoofoo %%
`= replace("foo123foo456foo", "\d+", "")` %% foo123foo456foo %%
前面在介绍 date() 函数时,我们提及过它不能解析使用 JavaScript 日期函数 new Date() 得到中国标准时间,现在我们来举一个并无实际用处的例子,而且还漏洞百出。下面是在文档 笔记二.md 中的 5 个任务:
- [ ] ChinaDate: Thu May 02 2024 23:19:23 GMT+0800 (中国标准时间)
- [ ] 日期:Sun Jan 23 2022 08:00:00 GMT+0800 (中国标准时间)
- [x] 去年:Mon Nov 13 2023 08:00:00 GMT+0800 (中国标准时间)
- [ ] 2023-08-20 灼灼出生
- [ ] 不包含日期
现在我们想要过滤掉不包含日期的任务,同时把日期提取出来,将中国标准时间显示成 xxxx-xx-xx 的日期格式,下面是作者的一个尝试参考:
TABLE Date, T.text
FLATTEN file.tasks AS T
FLATTEN {"Jan": "01", "Feb": "02", "Mar": "03", "Apr": "04", "May": "05", "Jun": "06", "Jul": "07", "Aug": "08", "Sep": "09", "Oct": "10", "Nov": "11", "Dec": "12"} AS monthObj
FLATTEN regextest("\d{4}-\d{2}-\d{2}", T.text) AS isRegularDate
FLATTEN regextest("([A-Z]+[a-z]{2}\s)+\d{2}\s\d{4}\s\d{2}:\d{2}:\d{2}\sGMT\+0800\s\(中国标准时间\)", T.text) AS isCHDate
WHERE file = this.file AND (isCHDate OR isRegularDate)
FLATTEN choice(isRegularDate, T.text, monthObj[split(T.text, " ")[1]]) AS Month
FLATTEN choice(isCHDate, split(T.text, " ")[2], "") AS Day
FLATTEN choice(isCHDate, split(T.text, " ")[3], "") AS Year
FLATTEN choice(isCHDate, Year + "-" + Month + "-" + Day, split(T.text, " ")[0]) AS Date
结果:

代码分析:
- 在代码中使用
FLATTEN xx AS xx语句来声明一个新的字段。 - 使用了
regextest()函数来匹配xxxx-xx-xx格式日期和中国标准时间日期。 - 使用
choice()函数来执 IF 类判断。 - 使用了
split()函数来将中国标准时间按空格分组并从数组中按索引获取日期数据,将月份英语表示替换成数字表示。 - 第一条任务解析失败了,因为
ChinaDate:后面有一个空格,导致日期提取时索引不对,所以这个方法很有局限性。同样在处理最后一条数据时,也是硬编码实现,一旦多个空格将导致结果解析出错。
从上面的例子分析来看:在 DQL 查询语句中不能实现字符提取操作(虽然有 substring() 和 slice() 函数可以提取子串,但是前提是要能够获取到匹配值的索引)。因此复杂的操作还是使用后面要讲解的 DataView JS 查询方式来实现。
starstwith / endswith 函数
这二个函数实用没有什么好讲解的,startswith(string, prefix) 函数用于判断字符串是否以给定的前缀开头。而 endswith(string, suffix) 函数则是以特定后缀结尾。
使用 startswith() 函数在获取“打造极致体验笔记”系列笔记文档:
TABLE file.name
WHERE startswith(file.name, "打造极致体验笔记")
padleft / padright 函数
这二个函数用于填充字符,在特定场景下比如格式化输出时用来填充空白还是可以的。padleft(string, length, [padding]) 用于在左边填充指定的 padding 字符,而 padright(string, length, [padding]) 则用于右边填充。在使用时需要注意 length 的值一定要大于 string 的长度不然没有任何作用。
split / substring / truncate 函数
这 3 个函数没有什么关联关系,只不过放在一起讲解罢了。
split(string, delimiter, [limit]) 函数的作用和前面介绍的 join() 函数操作相反,它用于将一个字符串按指定的分隔符 delimiter 来分割成数组,并且还提供了一个可选的结果数组返回长度限制 limit。
`= split("abcdefg", "", 3)` %% a, b, c %%
`= split(join(["a", "b", "c"], ""), "", 2)` %% a, b %%
substring(string, start, [end]) 函数用于获取字符串的一部分,需要注意的是它和数组切片 slice() 函数的区别:
`= substring("hello", 0, 2)` %% he %%
`= substring("hello", 2)` %% llo %%
`= substring("hello", -3, 4)` %% hell %%
`= slice(split("hello", ""), -3, 4)` %% l, l %%
从结果来看 substring() 函数是不接收负整数作为参数值,如果传入会当成 0 来处理,而 slice() 函数如果传入负整数,则是从尾部算起始元素的索引值,如:-3 则是从 hello 从尾向前数 3 个字符到第 2 个 l,相当于数组长度 5 + -3,从头数第 2 个元素(start 是包含的)l。
truncate(string, length, [suffix]) 函数用于将文本截断至指定的长度 length,需要注意的是这个长度需要将后缀 suffix 值 ... 算入。这个函数对于展示表格数据中单元格文本较长时非常有用。
`= truncate("hello world!", 9)` %% hello ... %%
`= truncate("hello world!", 9, "***")` %% hello *** %%
5. 辅助函数
default(field, value) 函数的作用是如果 filed 为空值,则返回 value 值。对于一个数组,我们可以使用 nonnull() 函数来移除空值,也可以使用 default() 函数来将空值替换成指定的默认值。如果想要保留空值,可以使用 ldefault() 函数,用法是一样的,只不过它不会替换掉 field 中的空值。
`= default(completed, "incompleted")` %% incompleted %%
`= default(undefined, 1)` %% 1 %%
`= default(null, 1)` %% 1 %%
`= default(false, 1)` %% false %%
`= default(object("b", null), 0)` %% b: - %%
`= default([0, null, 2, null, [4, null, [5, 6, undefined]]], 0)` %% 0, 0, 2, 0, 4, 0, 5, 6, 0 %%
`= ldefault([0, null, 2, null, [4, null, [5, 6, undefined]]], 0)` %% 0, -, 2, -, 4, -, 5, 6, - %%
从上面的示例来看空值包含 null 和 undefined 的值,但 false 和 "" 这样的假值是不算入内的。此我, default() 函数只适用于基础变量,数组值,不适用于对象。
choice 函数
choice(bool, left, right) 函数是一个原始的 if 语句,相当于 JavaScript 中的 ? : 运算符,没有 else 语句,只能进行一个条件判断,如果为真则执行 left 否则执行 right。这是唯一一个条件判断函数,因此使用较多,比如前面介绍判断中国标准时间的例子。
`= choice(true, "yes", "no")` %% yes %%
hash 函数
hash(seed, [text], [variant]) 函数用于生成一个基于给定种子(seed)、文本(text)和变体(variant)的哈希值。这里的种子如果提供不同的值会产生不同的哈希输出,相同的种子可以增加哈希函数的唯一性。变体可以提供进一步的文本区分依据,例如在同一个文件,相同的任务名,将 variant 设置为任务所在的行号可区分出同名的任务。
`= hash("1", "same text")` %% 673738316819763 %%
`= hash("2", "same text")` %% 6125302604555861 %%
`= hash("2", "same text", 1)` %% 3643262541303331 %%
`= hash("2", "same text", 2)` %% 27826704613653 %%
`= hash(dateformat(date(today), "YYYY-MM-DD"), this.file.name)` %% 6466914653753995 %%
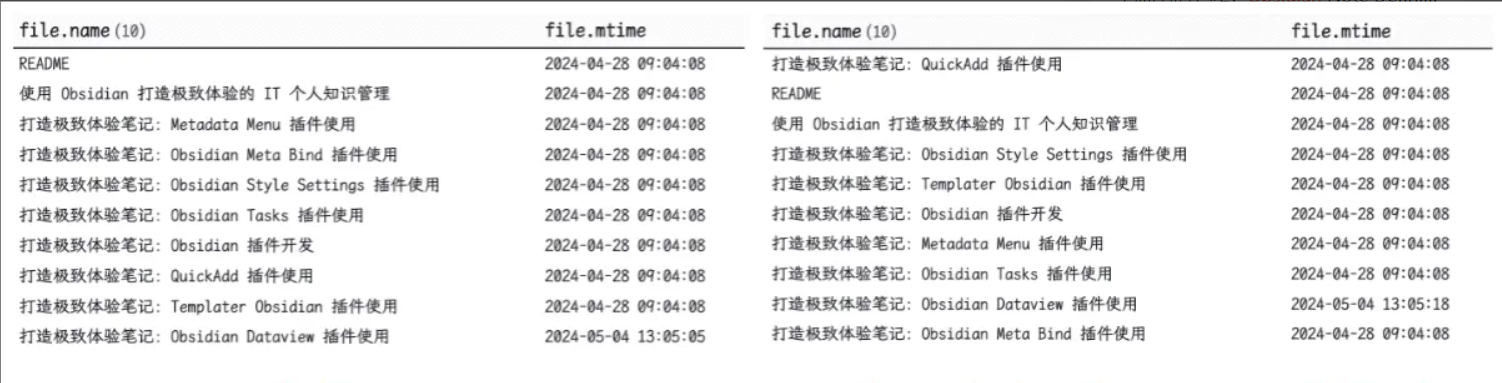
下面我们使用 hash() 函数来随机排序文档
TABLE WITHOUT ID file.name, file.mtime
SORT file.ctime
SORT hash(dateformat(file.ctime, "YYYY-MM-DD"), file.name)
结果:
striptime 函数
striptime(date) 函数用于去掉日期中的时间部分,只留下年、月和日。
`= striptime(this.file.ctime)` %% 2024-04-30 %%
dateformat 函数
dateformat(date|datetime, string) 函数用于格式化日期,格式化符号参见:Luxon tokens。
`= dateformat(this.file.ctime, "yyyy-MM-dd")` %% 2024-04-20 %%
`= dateformat(this.file.ctime, "HH:mm:ss")` %% 21:09:55 %%
`= dateformat(date(now),"x")` %% 1714802627234 %%
`= dateformat(date(now),"ffff")` %% 2024年5月4日星期六中国标准时间 14:10 %%
`= dateformat(date(now),"tttt")` %% 中国标准时间 14:11:31 %%
durationformat 函数
durationformat(duration, string) 函数用于格式化持续时间,在格式字符串中的单引号内的任何内容都不被视为标记格式内容。
可用的标记字符如下:
S毫秒s秒m分钟h小时d天w周M月y年
下面是简单使用举例:
`= durationformat(dur("3 days 7 hours 43 seconds"), "ddd'd' hh'h' ss's'")` %% 003d 07h 43s %%
`= durationformat(dur("30000 days 7 hours 43 seconds"), "ddd'd' hh'h' ss's'")` %% 30000d 07h 43s %%
`= durationformat(dur("3 days 7 hours 43 seconds"), "hh'h' ss's'")` %% 79h 43s %%
`= durationformat(dur("3 days 7 hours 43 seconds"), "ss'秒'")` %% 79 h 43 s %%
currencyformat 函数
currencyformat(number, [currency]) 函数用于格式化货币,其中 currency 常见取值有人民币(CNY),美元(USD),欧元(EUR),日元(JPY),更多国家的取值请参考:ISO 4217。
`= currencyformat(123456.789, "CNY")` %% ¥123,456.79 %%
`= currencyformat(123456.789, "USD")` %% US$123,456.79 %%
`= currencyformat(123456.789, "EUR")` %% €123,456.79 %%
`= currencyformat(123456.789, "JPY")` %% JP¥123,457 %%
从执行结果来看,currencyformat() 函数为我们自动将货币格式化成了千分位表示,同时我们还发现日本货币的结果和前面几个不太一样,这里暂时不追究为什么,因为只为写作示例而已。
localtime 函数
localtime(date) 函数用于将固定时区中的日期转换为当前时区中的日期。
`= localtime(date(now))` %% 9:07 下午 - 5 04, 2024 %%
meta 函数
meta(link) 函数用于获取链接的元数据信息,它返回一个对象包含以下几个属性:
display链接的别名,如果没有提供则为null,示例:meta([[打造极致体验笔记:Templater Obsidian 插件使用|这里就是display要显示的内容]]).display的值为这里就是display要显示的内容。embed用于判断链接是否为媒体文件嵌入,例如:meta(![[Pasted image 20240504133553.png]]).embed值为true。subpath链接的文档中的标题名或者段落 ID,例如:[[打造极致体验笔记:Obsidian Dataview 插件使用#\meta函数]].subpath的值为meta函数。如果引用的是文档中的段落,例如:meta([[My Project#^9bcbe8]]).subpath则值为9 bcbe 8type链接的类型,其值为file/header/block,分别表示链接的是文件、标题段落。