- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
DataArray 接口是 Dataview 提供的列表数据操作的抽象,它是对 JavaScript 数组操作的扩展和基于 Dataview 环境的本地化。我们可过 dv.array() 将一个普通的数组转换成 DataArray 类型,也可以反向操作将其转换成普通的 JavaScript 数组,比如:dv.list(dv.current()).array()。
下面是官方提供的 DataArray 接口定义,为了简少行数,删除了所有注释:
export type ArrayFunc<T, O> = (elem: T, index: number, arr: T[]) => O;
export type ArrayComparator<T> = (a: T, b: T) => number;
export interface DataArray<T> {
length: number;
where(predicate: ArrayFunc<T, boolean>): DataArray<T>;
filter(predicate: ArrayFunc<T, boolean>): DataArray<T>;
map<U>(f: ArrayFunc<T, U>): DataArray<U>;
flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>;
mutate(f: ArrayFunc<T, any>): DataArray<any>;
limit(count: number): DataArray<T>;
slice(start?: number, end?: number): DataArray<T>;
concat(other: Iterable<T>): DataArray<T>;
indexOf(element: T, fromIndex?: number): number;
find(pred: ArrayFunc<T, boolean>): T | undefined;
findIndex(pred: ArrayFunc<T, boolean>, fromIndex?: number): number;
includes(element: T): boolean;
join(sep?: string): string;
sort<U>(key: ArrayFunc<T, U>, direction?: "asc" | "desc", comparator?: ArrayComparator<U>): DataArray<T>;
groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U; rows: DataArray<T> }>;
distinct<U>(key?: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<T>;
every(f: ArrayFunc<T, boolean>): boolean;
some(f: ArrayFunc<T, boolean>): boolean;
none(f: ArrayFunc<T, boolean>): boolean;
first(): T;
last(): T;
to(key: string): DataArray<any>;
expand(key: string): DataArray<any>;
sum(): number;
avg(): number;
min(): number;
max(): number;
forEach(f: ArrayFunc<T, void>): void;
array(): T[];
[Symbol.iterator](): Iterator<T>;
[index: number]: any;
[field: string]: any;
}
接下来我们将分类介绍接口中的属性和方法的用法。
一、数据读取
一个数组通过索引来获取其对应的数据项的值是一个很常规的操作。这里我们有一个数组 arr,就可以通过 arr[0] 和 arr[arr.length - 1] 来分别读取第一项和最后一项的值,这对应 DataArray 中的 first() 和 last() 方法。如果数组项是一个对象值,想要获取读取对象中某个字段的值,就需要使用遍历方法,比如 for 语句,或者数组的 forEach() 方法,为了方便操作,DataArray 接口直接提供了一个通过属性来获取数组中对象值的方法 to(),也可以在 DataArray 实例中直接访问这个属性名。
```dataviewjs
const arr = [1, 2, 3]
const arr2 = [{name: 'jenemy', age: 34}, {name: 'xiaolu', age: 33}, {name: 'lulu', age: 25 }]
const dvArr = dv.array(arr)
const dvObjArr = dv.array(arr2)
console.log(dvArr.length) // 3
console.log(dvArr.first(), dvArr.last()) // 1 3
console.log(dvArr[0], dvArr[dvArr.length - 1]) // 1 3
console.log(dvObjArr.name.array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr['name'].array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr.to('name').array()) // ['jenemy', 'xiaolu', 'lulu']
console.log(dvObjArr[0]) // {name: 'jenemy', age: 34}
// 通过遍历获取属性值
for (p of dvObjArr) {
console.log(p.name) // jenemy, xiaolu, lulu
}
// 使用 `.forEach()` 遍历
dvObjArr.forEach(p => console.log(p.name)) // jenemy, xiaolu, lulu
二、数字运算
提供了对于数字的几个常见运算,如求和、求平均值、最大值和最小值。这个和 DQL 查询语言中的功能一致。
```dataviewjs
const arr = dv.array([2, 3, 1, 8, 4, 6, 5, 7, 9])
console.log(arr.sum()) // 15
console.log(arr.min()) // 1
console.log(arr.max()) // 9
console.log(arr.avg()) // 5
三、数据遍历
数据遍历除了使用 for 和 for of 语句外,DataArray 接口中还定义了很多遍历方法,有的是 JavaScript 中相同的,有的是 Dataview 特有的。
1. forEach()方法
方法签名为:forEach(f: ArrayFunc<T, void>): void,对数组的每一项执行指定的函数。
```dataviewjs
dv.array([1, 2, 3, 4, 5]).forEach(n => dv.span(n)) // 页面显示:12345
2. map()方法
方法签名为:map<U>(f: ArrayFunc<T, U>): DataArray<U>,对数组中的每一项执行指定的函数,并返回一个值。
```dataviewjs
dv.list(dv.array([1, 2, 3, 4, 5]).map(x => x * 2)) // 渲染列表:2, 4, 6, 8, 10
dv.list(dv.array([1, 2, 3, 4, 5]).map(x => x % 2 === 0)) // 渲染列表:false, true, false, true, false
3. mutate()方法
方法签名为:mutate(f: ArrayFunc<T, any>): DataArray<any>,这个方法实际上是对 map() 遍历对象数组操作的一种特定场景下的简化操作。
下面我们一步步来追本溯源,解读其适用的场景。
我们知道使用 map() 方法可以对普通数组(如:[1, 2, 3, 4]),执行遍历操作如:x => x * 2 或者 x => x % 2 === 0 来返回布尔值,但是我们无法使用 mutate() 来实现同样的功能。
接下来我们看一下对象数组(如:const arr = [{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}]),使用 map() 方法我们可以执行操作 x => x.a + x.b,但是同样在 mutate() 方法中无法使用。接下来通过 map() 方法为对象添加一个属性 c,代码为:x => {x.c = x.a + x.b; return x},然后我们这次发现可以使用 mutate() 发挥作用了:arr.mutate(x => x.c = x.a + x.b),进一步我们尝试:arr.mutate(x => delete x.b) 以及 arr.mutate(x => x.b = x.a + x.b)。
总结:mutate() 方法适用于修改遍历项(仅对象)的值,如添加属性、删除属性以及修改属性值操作。它是在不改变遍历项数据类型情况下,map() 方法的一种简化操作。
下面我们看一下在实际操作中的运用。
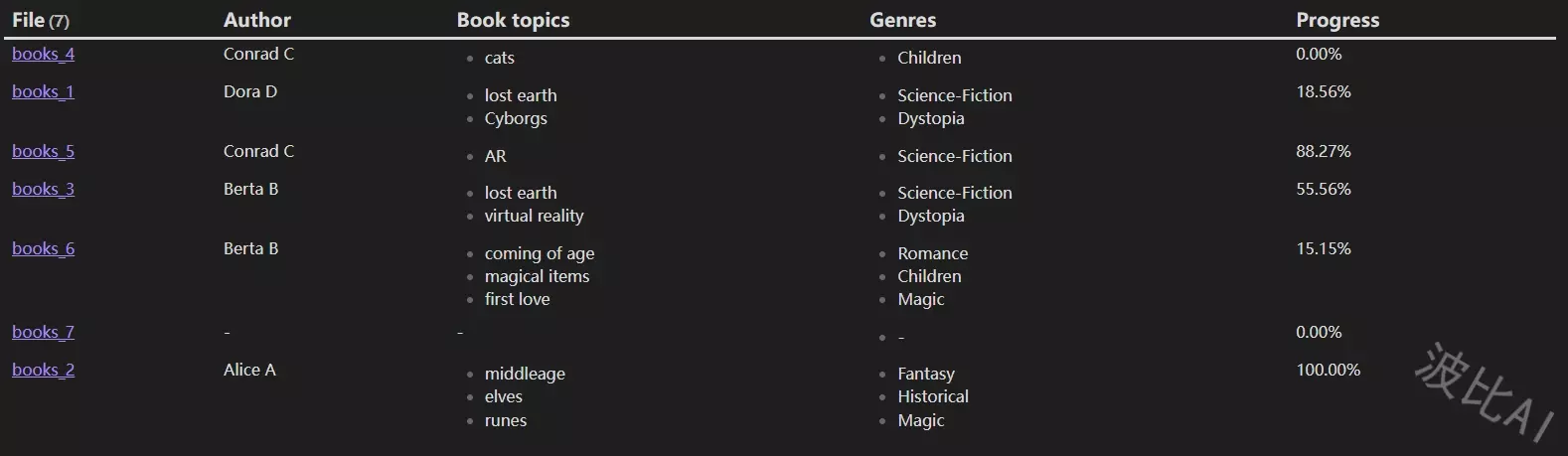
```dataviewjs
dv.table(["File", "Author", "Book topics", "Genres", "Progress"], dv.pages('"10 Example Data/books"')
.mutate(b => b.percent = (b.pagesRead / b.totalPages * 100).toFixed(2) + "%")
.map(b => [b.file.link, b.author, b.booktopics, b.genres, b.percent]))
结果:
4. flatMap()方法
方法签名为:flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>,通过对数据数组中的元素应用函数来映射每个元素,然后展平结果以生成新数组。
这是一个很重要的方法,应用得当在很多场景下能够简化操作,但是这个方法初次接触有点不好理解,下面我们来一一解读其用法。
首先我们将在 mutate() 方法讲解时我们使用的简单数组 [1, 2, 3, 4] 和 const arr = [{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}] 使用 flatMap() 方法进行同样操作:
```dataviewjs
const arr = dv.array([{a: 1, b: 2}, {a: 3, b: 4}, {a: 5, b: 6}])
dv.list(dv.array([1, 2, 3, 4]).flatMap(x => [x * 2])) // 页面显示 [2, 4, 6, 8]
dv.list(dv.array([1, 2, 3, 4]).flatMap(x => [x % 2 === 0])) // 页面显示 [false, true, false, true]
dv.list(arr.flatMap(x => [x.a + x.b])) // 页面显示 [3, 7, 11]
dv.list(arr.flatMap(x => {x.c = x.a + x.b; return [x]})) // 页面显示 [{a: 1, b: 2, c: 3}, {a: 3, b: 4, c: 7}, {a: 5, b: 6, c: 11}]
结果:

从上面的示例可以看出,使用 flatMap() 方法改写 map() 方法只需要将结果套上一层数组。
读者可能会疑惑,就这还需要单独搞一个方法出来多此一举吗?其实不然,下面我们来揭示其真正发挥作用的地方。
在使用 map() 方法时不会改变数组的长度,这是一个共识。现在我想把数组 [1, 2, 3, 4] 变成 [1, 2, [3], 2, 3, [5], 3, 4, [7]],其中嵌套数组值为第 i 项加上 i + 1 项的值,其中 i 为数组索引。这个时候就无法使用 map() 来实现了,需要使用 for 语句或者 forEach() 方法来遍历数组,然后声明一个新的数组来存放结果:
```dataviewjs
const arr = dv.array([1, 2, 3, 4])
const result = []
for (let i = 0; i < arr.length; i++) {
if (i < arr.length - 1) {
result.push(arr[i], arr[i + 1], [arr[i] + arr[i + 1]])
}
}
console.log(result) // [1, 2, [3], 2, 3, [5], 3, 4, [7]]
那么使用 flatMap() 实现如何呢?
很简单,只需要一行代码:arr.flatMap((x, i, arr) => i < arr.length - 1 && [arr[i], arr[i + 1], [arr[i] + arr[i + 1]]]).array()。
上面的示例我们使用 flatMap() 实现了数组增加元素的操作,接下来我们来看一下如何删除元素。
我们通常使用 filter() 方法来过滤数据,如 [1, 2, 3, 4].filter(x => x % 2 === 0) 来得到偶数组成的数组,而使用 flatMap() 删除不需要的数组项,只需要返回 [] 即可,如:[1, 2, 3, 4].flatMap(x => x % 2 === 0 ? [x] : [])。
最后,说一下 flatMap() 之所以叫这个名字,是因为它实际上是先执行了 map() 操作,然后再执行了深度为 1 的 flat() 操作。
```dataviewjs
const arr = [{a: 1, b: 2, c: [1, 2]}, {a: 3, b: 4, c: [3, 4]}, {a: 5, b: 6, c: [5, 6]}]
console.log(arr.map(x => x.c).flat()) // [1, 2, 3, 4, 5, 6]
console.log(arr.flatMap(x => x.c)) // [1, 2, 3, 4, 5, 6]
四、数据查询与过滤
在 JavaScript 中数据数据查询通常使用 find()/findIndex()/findLastIndex(), includes() 和 indexOf()/lastIndexOf() 这几种方法,而过滤则使用 filter()。在 DataArray 中支持 find()/findIndex(), includes(),indexOf() 和 filter() 方法。
1. where()方法
在 Dataview 中我们通常使用 where(predicate: ArrayFunc<T, boolean>): DataArray<T> 方法来过滤数据,同样也可以使用 filter() 方法,两者是一样的,只不过后者是 JavaScript 中数组的常用方法。
下面我们接着讲解 mutate() 方法时使用的书籍查询示例,加上一个条件判断:
```dataviewjs
dv.table(["File", "Author", "Book topics", "Genres", "Progress"], dv.pages('"10 Example Data/books"')
.where(b => b.author === "Dora D" && b.genres.includes("Dystopia"))
.mutate(b => b.percent = (b.pagesRead / b.totalPages * 100).toFixed(2) + "%")
.map(b => [b.file.link, b.author, b.booktopics, b.genres, b.percent]))
结果:

[!warning] 需要注意的是使用where()方法查询数据时可能会修改原始数据
下面以 filter() 方法来举例:
const arr = [1, 2, 3, 4, 5, 6]
const result = arr.filter((d, i, arr) => {
if (i < arr.length - 1) arr[i + 1] += 10
return d < 5
})
console.log(result, arr) // [1] (6) [1, 12, 13, 14, 15, 16]
const arr2 = [1, 2, 3, 4, 5, 6]
const result2 = arr2.filter((d, i, arr) => {
arr.push(3)
return d < 4
})
console.log(result2, arr2) // [1, 2, 3] (12) [1, 2, 3, 4, 5, 6, 3, 3, 3, 3, 3, 3]
const arr3 = [1, 2, 3, 4, 5, 6]
const result3 = arr3.filter((d, i, arr) => {
arr.pop()
return d < 5
})
console.log(result3, arr3) // [1, 2, 3] (3) [1, 2, 3]
对 arr 的过滤中我们将当前遍历的数据项的下一项执行了加 10 操作,导致第 2 次执行时其值为 12,依次类推,最终只有第一次执行时满足过滤条件。
对 arr2 的过滤中我们每执行一次过滤函数就在数组的后面加上数字 3,观察结果并没有对扩充后的数据项进行遍历,因为这会进入一个死循环。
对 arr3 的过滤中我们每执行一次过滤函数就从数组尾部移出一个元素,这最终导致执行 3 次后已再元小于 5 的元素了,因为 4 已经移出数组了。
2. find()和findIndex()方法
find(pred: ArrayFunc<T, boolean>): T | undefined 方法返回数组中满足提供的测试函数的第一个元素的值,否者返回 undefined。如果需要查询某个值的索引,则使用 findIndex(pred: ArrayFunc<T, boolean>, fromIndex?: number): number 方法。
下面我们通过这两个方法来找出 6:00-6:30 第一次早起的日期和在日记中记录的索引位置,需要注意的是由于第一篇日记没有相关数据,所以这里的 index 结果为 2。
```dataviewjs
const dt = dv.luxon.DateTime
const link = dv.pages('"10 Example Data/dailys"').find(p => {
const wakeUpTime = p['wake-up'] && dt.fromFormat(p['wake-up'], 'HH:mm').startOf('minute')
const start = dt.fromObject({ hour: 6, minute: 0 }).startOf('minute')
const end = dt.fromObject({ hour: 6, minute: 30 }).startOf('minute')
return wakeUpTime > start && wakeUpTime < end
}).file.link
const index = dv.pages('"10 Example Data/dailys"').findIndex(p => {
const wakeUpTime = p['wake-up'] && dt.fromFormat(p['wake-up'], 'HH:mm').startOf('minute')
const start = dt.fromObject({ hour: 6, minute: 0 }).startOf('minute')
const end = dt.fromObject({ hour: 6, minute: 30 }).startOf('minute')
return wakeUpTime > start && wakeUpTime < end
})
dv.span(`第 ${index + 1} 天(${link})开始 6:00-6:30 早起`)
3. includes()方法
includes(element: T): boolean 方法用于判断数组中是否包含某个数据项。
对于数组 [1, 2, 3] 我们可以使用 dv.array([1, 2, 3]).includes(2) 来判断 2 是否在数组中。下面是一个判断页面是否在日记目录中的示例:
```dataviewjs
console.log(dv.pages('"10 Example Data/dailys"').includes(dv.page("2022-01-12"))) // true
console.log(dv.pages('"10 Example Data/dailys"').includes(dv.page("2023-01-12"))) // false
4. indexOf()方法
indexOf(element: T, fromIndex?: number): number 方法返回数组中第 fromIndex 次出现给定元素的下标,如果不存在则返回 -1。这个方法的使用场景目前作者能想的是多个同名文件(如未命名的)的查找,不过这里不打算这个作为示例,而是以普通的数字数组更方便直白。
```dataviewjs
const data = dv.array([1, 2, 3, 2, 45, 23, 2, 32, 43242, 5435, 2, 23])
console.log(data.indexOf(2)) // 1
console.log(data.indexOf(2, data.length - 1)) // -1
console.log(data.indexOf(2, 4)) // 6
五、测试判断
在 JavaScript 中可以通过数组的 every() 方法测试一个数组内的所有元素是否都能通过指定函数的测试,使用 some() 方法测试数组中是否至少有一个元素通过了由提供的函数实现的测试。如果在数组中找到一个元素使得提供的函数返回 true,则返回 true;否则返回 false。而 DataArray 同样也提供了这两个方法,同时还提供了一个和 every() 相反的 none() 方法。
```dataviewjs
const data = dv.array([11, 20, 23, 43, 123, 13, 55])
console.log(data.every(item => item > 10)) // true
console.log(data.none(item => item > 10)) // false
console.log(data.some(item => item > 100)) // true
六、分组与展开操作
在 DQL 查询语句中我们使用 GROUP BY 来将数据按指定的字段进行分组,而使用 FLATTEN 来对查询结果进行展开。但是在使用 API 时我们需要自己来解析分组后的数据,可自定义渲染,虽然很灵活,但是也增加了成本。
DataArray 接口提供了 groupBy() 方法来对数据进行分组,expan() 方法来展开数据。
1. groupBy()方法
方法的签名为: groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U; rows: DataArray<T> }>,第一个参数为一个函数,一般返回字段名称,后续会介绍其它用法。第二个参数为一个比较函数,默认情况下按升序排序。
groupBy() 方法调用后返回一个结果数组,数组项为一个对象,其中 key 属性表示分组的名称,rows 表示分组的数据。
为了方便理解,接下来我们将采用 DQL 和 API 对比的方式来举例。
示例一:一对多分组
下面我们来查询书籍并按作者进行分组。这个示例中一个作者对应多本书籍,因此我们需要将分组后的数据 rows 进行展开。
```dataview
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
```dataviewjs
dv.table(['作者', '书籍'], dv.pages('"10 Example Data/books"')
.groupBy((p) => p['author'])
.flatMap(p => {
const result = []
if (p.rows.length > 1) {
p.rows.forEach((r, i) => {
if (i > 0) {
result.push(['', r])
} else {
result.push([p.key, r])
}
})
} else {
result.push([p.key, p.rows.first()])
}
return result
})
.map(r => {
return [r[0], r[1].file.link]
}))
</code></pre>
结果:
<img src="https://ax6s.yidacp.com:1018/i/2025/02/01/679dd664a13d7.webp" alt="" />
<strong>示例二:多对多分组</strong>
同样是查询书籍信息,这次我们查询书籍的分类信息。这是一个多对多的关系,一本书可以归为多种类型,而一个类型也可以包含多本书籍。
在使用 DQL 查询语言时,需要注意一点,我们使用了 <code>FLATTEN</code> 语句来展开分类,让每一个分类对应一本书籍,不然就会显示成多个分类对应一本书籍,这显然不符合结果。
在使用 API 处理这种多对多分组时,我们就需要分别对 <code>key</code> 和 <code>rows</code> 进行遍历展开才能得到和 DQL 查询<del>类似</del>的结果。
<pre><code class="language-yaml line-numbers">```dataview
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
FLATTEN genres
GROUP BY genres AS 类别
```dataviewjs
dv.table(['类别', '书籍'], dv.pages('"10 Example Data/books"')
.groupBy((p) => p['genres'])
.flatMap(p => {
const result = []
if (p.rows.length > 1) {
p.rows.forEach((r, i) => {
if (i > 0) {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, r])
})
} else {
result.push([p.key, r])
}
} else {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, r])
})
} else {
result.push([p.key, r])
}
}
})
} else {
if (Array.isArray(p.key)) {
p.key.flatMap(k => {
result.push([k, p.rows.first()])
})
} else {
result.push([p.key, p.rows.first()])
}
}
return result
})
.sort(p => p[1].file.name)
.sort(p => p[0])
.flatMap((r, i, arr) => {
if (!r) return []
const result = []
const key = r[0]
for (j = i; j < arr.length; j++) {
if (i === j) {
let exist = false
// 如果已经存在就不再添加
for (let k = j - 1; k > 0; k--) {
if (key === arr[k][0]) {
exist = true
break
}
}
if (!exist) {
result.push(r)
} else {
result.push(['', arr[j][1]])
}
} else {
if (arr[j][0] === key) {
result.push(['', arr[j][1]])
arr.splice(j, 1)
}
}
}
return result
})
.map(r => {
return [r[0], r[1].file.link]
}))
</code></pre>
结果:
<img src="https://ax6s.yidacp.com:1018/i/2025/02/01/679dd6a0be41e.webp" alt="" />
上述代码虽然我们实现了类似的结果,但是观察结果会发现我们丢失了分组信息:原数据有 8 个分组,我们的结果为 13 个分组。代码中,通过两个 <code>sort()</code> 方法分别按分组分类名和文件名进行了排序;通过两个 <code>flatMap()</code> 方法分别处理了文档名称的展开和分类同名的空白显示。
<strong>示例三:根据计算结果分组</strong>
下面这个示例我们不返回字段名,而是返回一个根据条件判断自定义的名称。
<pre><code class="language-yaml line-numbers">```dataview
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
```dataviewjs
dv.list(dv.pages('"10 Example Data/assignments"')
.groupBy(p => {
if (p.due < dv.date("2022-05-12")) {
return "已过期"
}
return "还有机会"
})
.flatMap(g => {
return [g.key, g.rows.map(r => r.file.link)]
}))
</code></pre>
结果:
<img src="https://ax6s.yidacp.com:1018/i/2025/02/01/679dd71794771.webp" alt="" />
从结果来看还是有细微差别的,左边分组名和数据是放置在一个 <code><li></code> 标签中,而右边则是将分组名和数据单独放置在一个 <code><li></code> 标签中。
<h3>2. expand()方法</h3>
<code>expand(key: string): DataArray<any></code> 方法的作用不同于 <code>FLATTEN</code> 语句,它可以用于列表和任务的展开,需要指定 <code>key</code> 为 <code>children</code> 或者 <code>subtasks</code>,但是结果不能保证是按原来的顺序输出。
这个方法在 Dataview Example Valut 示例库也没有找到相应的示例,说明其适用范围很小,很冷门。作者本以为能够实现将嵌套的任务展开,然而却...
<pre><code class="language-yaml line-numbers">- [ ] 1
- [ ] 2
- [ ] 3
- [ ] 4
- [ ] 5
- [ ] 6
```dataviewjs
dv.list(dv.current().file.tasks.expand('subtasks').map(t => t.text))
dv.taskList(dv.current().file.tasks.expand('subtasks'))
结果:

七、其他方法
sort() 方法有在前面的示例中应用到,剩下的都比较简单,直接上示例:
```dataviewjs
const arr = dv.array([1, 2, 3, 4, 2, 1, 23, 12])
console.log(arr.distinct().array()) // [1, 2, 3, 4, 12, 23]
console.log(arr.join('#')) // 1#2#3#4#2#1#23#12
console.log(arr.limit(2).array()) // [1, 2]
console.log(arr.slice(0, 3).array()) // [1, 2, 3]
console.log(arr.concat(dv.array([5, 6, 7, 8])).array()) // [1, 2, 3, 4, 2, 1, 23, 12, 5, 6, 7, 8]