- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
现在开始我们来介绍在入门中没有提及到的方法,这些知识点会让你应对复杂的需求时更加游刃有余,有更多的思路。
一、更多页面获取方式
在前面的示例中我们使用 dv.current() 来获取代码所在当前页面,使用 dv.page(path) 来获取单个文档页面,使用 dv.pages(source) 来获取指定目录的文档。现在我们来进一步了解 dv.pages() 的其它用法。
```dataviewjs
dv.list(dv.pages().limit(5).map(p => p.file.link)) // 获取所有页面,返回前5个链接
dv.list(dv.pages('#daily').limit(5).map(p => p.file.link)) // 获取所有带有daily标签的页面,返回前5个链接
dv.list(dv.pages('#daily or #clientC').map(p => p.file.link)) // 获取所有带有daily或clientC标签的页面,返回链接列表
dv.list(dv.pages('"10 Example Data/books" and -(#daily and #journal)').map(p => p.file.link)) // 获取目录名为"10 Example Data/books"且不带有daily和journal标签的页面,返回链接列表
dv.list(dv.pages('"10 Example Data/books" or #clientC').map(p => p.file.link)) // 获取目录名为"10 Example Data/books"或带有clientC标签的页面,返回链接列表
[!tip] 需要注意的是目录名必需加上双引号,然后再放在单引号内
如果只相要获取文档的完整路径,可以直接使用 dv.pagePaths(source) 方法,如将所有路径以列表显示:dv.list(dv.pagePaths('#daily'))。
结果:
二、插入链接
作者有在这个系列的教程中的 DQL 查询语言篇中详细介绍了内部和外部链接以及双链的概念,现在我们来看一下在 API 中如何操作链接。
在 Obsidian 中使用链接来唯一描述一个文档、标题和块。在 Dataview 中定义了 Link 类来描述链接,它有以下属性:
path: string表示链接指向的文件路径。display?: string链接的显示名称,为可选字段。subpath?: string如果存在的话就指向文件内部的标题或者块 ID。embed: boolean是否为嵌入的链接。type: "file" | "header" | "block"链接的类型,会影响到subpath的结果。
1. 获取链接元数据
在 DQL 查询语言中我们使用 meta() 函数来获取链接的元数据信息,而在 API 中则将其拆分成 3 个独立的函数,分别对应其 type 的 3 种类型。
dv.fileLink(path, [embed?], [display-name])对应类型为file,用于链接文件。dv.sectionLink(path, section, [embed?], [display?]对应类型header,用于链接文档中的标题。dv.blockLink(path, blockId, [embed?], [display?]对应类型block,用于链接文档中的段落。
```dataviewjs
console.log(dv.fileLink("2022-02-04")) // Link {path: '2022-02-04', display: undefined, subpath: undefined, embed: false, type: 'file'}
console.log(dv.fileLink("2022-02-04", true)) // Link {path: '2022-02-04', display: undefined, subpath: undefined, embed: true, type: 'file'}
console.log(dv.fileLink("2022-02-04", false, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: undefined, embed: false, type: 'file'}
console.log(dv.sectionLink("2022-02-04", 'Metadata', false, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: 'Metadata', embed: false, type: 'header'}
console.log(dv.blockLink("2022-02-04", '220763', true, '显示名称')) // Link {path: '2022-02-04', display: '显示名称', subpath: '220763', embed: true, type: 'block'}
2. 页面中显示链接
要在文档中显示我们通过 dv.fileLink() 等方法创建的链接,只需要使用在入门中提及的渲染 HTML 方法即可。
这里我们来使用 dv.span() 渲染来展示块引用的效果:
```dataviewjs
dv.span(dv.blockLink("2022-02-04", '220763', true, '显示名称'))
[!Tip] 在 obsidian 中我们使用
[[]]来嵌入链接,如果所指向的文件不存在,在鼠标点击链接时会自动创建这个链接文件。如果相要将嵌入的链接的内容显示出来只需要在双括号前加一个感叹号,即![[]],这就等同于在代码中将embed设置为true,这个时候display指定的名称将会失效。
三、日期和时间操作
我们知道在 Obsidian 中的每一个文档都有一个 file 对象内部属性,其 cday / ctime 和 mday / mtime 分别表示文档的创建日期和时间以及修改日期和时间。
在创建日记类文档时,会自动以当前日期作为文件名。为此,在 file 对象中还提供了一个属性 day 来获取这个日期文件名(即返回日期值)。
在 API 中 Dataview 提供了 dv.date(text) 和 dv.duration(text) 来分别表示日期和时间以及持续时间。它们的返回值分别对应于底层的 dv.luxon.DateTime 和 dv.luxon.Duration 对象。关于 Luxon 日期和时间操作库我们会在文章中单独介绍其用法。
```dataviewjs
const now = new dv.luxon.DateTime(new Date())
const dur = dv.luxon.Duration
console.log(dv.date("2022-02-04").toFormat("yyyy-MM-dd")) // 2022-02-04
console.log(dv.date(dv.blockLink("2022-02-04", '220763', true, '显示名称')).toISODate()) // 2022-02-04
console.log(dv.date(now).toISOTime()) // 11:32:58.843+08:00
console.log(dv.date(now).offsetNameLong) // 中国标准时间
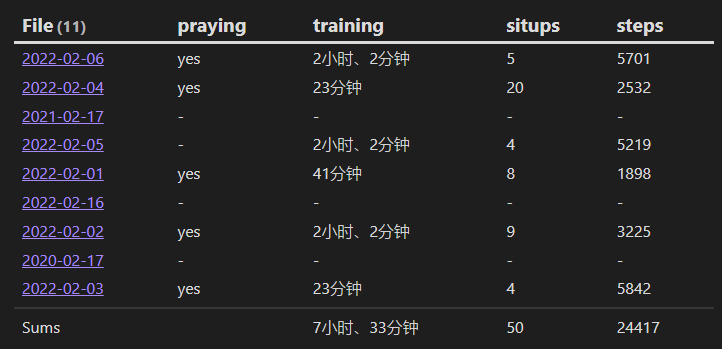
console.log(dv.duration('8h30m').toObject()) // {hours: 8, minutes: 30}
console.log(dv.duration('8h30m').toFormat("h'小时'm'分钟'")) // 8小时30分钟
console.log(dv.duration('8h30m').toHuman()) // 8小时、30分钟
console.log(dv.duration(dur.fromObject({hours: 8, minutes: 30})).toHuman()) // 8小时、30分钟
四、查询评估
这里介绍的方法对于基于 Dataview API 进行二次开发的读者或许有帮助。使用这些方法我们可以对 Dataview 的查询结果进行评估:添加/删除值、改变文档路径、强制显示/不显示分组 ID 以及对查询过程中出现报错进行捕捉处理等。
1. dv.query() 和 dv.tryQuery() 方法
dv.query(source, [file, settings]) 执行 Dataview 查询并将结果作为结构化返回返回。这里的 source 为 DQL 查询语句,因此我们可以得到 4 种结构化的输出类型。
在 Dataview 源码中将查询结果声明为类型 QueryResult,这是一个联合类型,下面是相关的源码:
export type IdentifierMeaning = { type: "group"; name: string; on: IdentifierMeaning } | { type: "path" };
export type TableResult = { type: "table"; headers: string[]; values: Literal[][]; idMeaning: IdentifierMeaning };
export type ListResult = { type: "list"; values: Literal[]; primaryMeaning: IdentifierMeaning };
export type TaskResult = { type: "task"; values: Grouping<SListItem> };
export type CalendarResult = {
type: "calendar";
values: {
date: DateTime;
link: Link;
value?: Literal[];
}[];
};
export type QueryResult = TableResult | ListResult | TaskResult | CalendarResult;
从上面的 TypeScript 类型声明来看,符合我们已知的 4 种查询类型 table | list | task 和 calendar,每一种类型都有其特殊的数据结构。
下面我们单独介绍每一种类型,但会在第一个 TableResult 类型中重点介绍相关的知识点,后面几种不再详细描述细节。同时,还会在第一个类型中介绍可选参数 file 和 settings 的作用。
(1)TableResult 类型
我们使用前面提到过的书籍查询例子,并将结果使用输出为 JSON 格式。
```dataviewjs
const query = `
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
`
const queryResult = await dv.query(query)
console.log(JSON.stringify(queryResult))
下面是控制台中输出的数据,我们将其中文件元数据使用 Link 来指代,这样有利于关注重要部分。
{
"value": {
"type": "table",
"values": [
[ null, [ Link ] ],
[ "Alice A", [ Link ] ],
[ "Berta B", [ Link, Link ] ],
[ "Conrad C", [ { Link }, { Link } ] ],
[ "Dora D", [ { Link } ] ]
],
"headers": [
"作者",
"书籍"
],
"idMeaning": {
"type": "group",
"name": "作者",
"on": {
"type": "path"
}
}
},
"successful": true
}
我们现在来分析一下上面这个结果 JSON 数据:
successful 值为 true 意味着查询是成功的。如果我们提供的数据不存在但是查询语法是正确的,那么 successful 仍然为 true,只不过 value.values 结果为 []。另外一种情况就是查询语法不正确,这种情况下就会返回 false,并且会返回一个类似:Failure {error: ‘Error: \n– PARSING FAILED … \n’, successful: false} 的信息。
如果去翻阅这部分的源码会发现上实际上 dv.query() 和 dv.tryQuery() 的区分在于返回结果,前者将结果使用 Success 和 Failure 类型包裹了一下,而后者没有。
value 属性中包含了查询结果数据的相关信息,其中 type 表明了结果类型为表格,values 为结果数据,headers 为表格的表头名称,idMeaning 为一个对象,其中 type 为 group 表明使用了分组,如果我们没有使用 GROUP BY 语句,这里将会是 path 值,同时也不会有 name 和 on 属性值。name 是在使用 GROUP UP 语句时指定 AS 名称,而 on 的值始终为 { type: “path” }。
分析完结果数据,现在我们来看一下可选参数 file 和 settings 的作用。
file 默认为当前代码所在文档的路径,格式为 xxx.md,我们可以通过传入自定义的路径来修改这个值。这个可选参数有什么用途呢?目前作者对 Obsidian 探索还不够深入,就留给读者去挖掘,这里在给出一个示例来演示其作用。
```dataviewjs
const query = `
TABLE WITHOUT ID file.link AS 替换后文件
WHERE file = this.file
`
const currentFile = dv.current().file
const queryResult = await dv.query(query, '实例候选.md')
queryResult.value.headers.push('原来的文件')
queryResult.value.values[0].push([currentFile.link])
dv.table(queryResult.value.headers, queryResult.value.values)
结果:
[!tip]
dv.query()方法返回值签名为Promise<Result<QueryResult, string>>,因此我们需要使用await dv.query()来获取异步值,然后也可以使用dv.query().then(v => {//...})以 Promise API 方式来处理。
settings 可先参数是一个 QueryApiSettings 类型,目前只有一个配置属性 forceId: boolean,这个值将覆盖 WITHOUT ID 的设置。当值为 true 时会包含链接或者分组名字段,false 则排序。
修改上面介绍 file 参数的示例中的 dv.query() 为 dv.query(query, '实例候选.md', { forceId: true }),会得到一个显示文件链接的结果:
(2)ListResult 类型
这里我们同样使用前面分组时的示例,来看一下解析后数据:
```dataviewjs
const query = `
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
`
const queryResult = await dv.query(query)
console.log(JSON.stringify(queryResult))
结果:
{
"value": {
"type": "list",
"values": [
{
"$widget": "dataview:list-pair",
"key": "还有机会",
"value": [ Link, Link, ... ]
},
{
"$widget": "dataview:list-pair",
"key": "已过期",
"value": [ Link, Link, ... ]
}
],
"primaryMeaning": {
"type": "group",
"name": "choice(due < date(\"2022-05-12\"), \"已过期\", \"还有机会\")",
"on": {
"type": "path"
}
}
},
"successful": true
}
从结果数据来分析,会发现在 primaryMeaning.name 中,分组字段不是一个常规的属性名,而是一个条件判断语句。在结果中我们还发现有一个特殊的字段 $widget。如果试图将其删除,那么在使用 dv.list(queryResult.value.values) 时将会得到一个错误提示结果:-
Dataview 目前定义了 2 种类型分别为 ListPairWidget ID 为 dataview:list-pair 和 ExternalLinkWidget ID 为 dataview:external-link。我们可以根据其定义来强制将 ListPairWidget 显示为 ExternalLinkWidget
。
下面是演示代码:
```dataviewjs
const query = `
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
`
const queryResult = await dv.query(query)
queryResult.value.values.forEach(row => {
row.value = row.value.slice(0, 2)
row.display = row.key
row.$widget = 'dataview:external-link'
})
dv.list(queryResult.value.values)
结果:

(3)TaskResult 类型
用于表示任务类查询的结果。我们可以遍历所有任务将未完成的任务强制完成,或者改变任务中的任何属性,需要注意的是由于在 Dataview 结果或者任务原始位置将任务状态改变,Dataview 都会重新执行查询。如果在查询结果中改变状态,而代码中又将其全部标记为已完成,这会陷入一个死角,所以不建议在文档的代码区域来改变任务的状态信息,而是结合 Obsidian 的命令来一健完成或取消完成任务更加合理。
下面给出一个改变任务状态的示例代码:
```dataviewjs
const query = `
TASK
WHERE file = this.file
`
const queryResult = await dv.query(query)
queryResult.value.values.forEach(row => {
row.annotated = true
row.checked = true
row.completed = true
row.fullCompleted: true
row.status = 'x'
})
dv.taskList(queryResult.value.values)
(4)CalendarResult 类型
我们在前面说过 Dataview API 并没有提供输出日历的方法,因此这里我们解析出来的日历数据就得另寻他法来渲染。我们这里就不再额外说明了,有一个渲染年度日历数据的案例会在我们系列文章的第 3 篇进行讲解。
这一小节最后再说一下 dv.tryQuery() 方法,它的使用和 dv.query() 一样,只不过没有 Success 和 Failure 类型封装,而是直接返回 { type: 'xx', values: 'xx' } 结构的数据,对于 TableResult 类型的数据其在 value 中的属性也自动变成 { type: 'xx', headers: [xx], idMeaning: {...}, values: [...]} 的结构。最后如果不符合 DQL 查询语法会直接在文档中抛出错误。
2. dv.queryMarkdown() 和 dv.tryQueryMarkdown() 方法
这 2 个方法的实际用法同 dv.query() 和 dv.tryQuery(),只不过它是将结果以 Markdown 语法原始格式输出。
```dataviewjs
const query = `
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
`
const queryResult = await dv.tryQueryMarkdown(query)
console.log(queryResult)
dv.paragraph(queryResult)
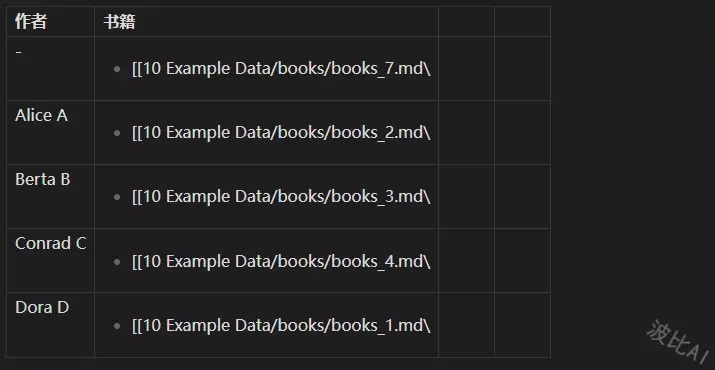
输出的 Markdown 格式结果:
| 作者 | 书籍 |
| -------- | ----------------------------------------------------------------------------------------------------------------------- |
| \- | <ul><li>[[10 Example Data/books/books_7.md\\|books_7]]</li></ul> |
| Alice A | <ul><li>[[10 Example Data/books/books_2.md\\|books_2]]</li></ul> |
| Berta B | <ul><li>[[10 Example Data/books/books_3.md\\|books_3]]</li><li>[[10 Example Data/books/books_6.md\\|books_6]]</li></ul> |
| Conrad C | <ul><li>[[10 Example Data/books/books_4.md\\|books_4]]</li><li>[[10 Example Data/books/books_5.md\\|books_5]]</li></ul> |
| Dora D | <ul><li>[[10 Example Data/books/books_1.md\\|books_1]]</li></ul>
在文档中的渲染结果:
3. dv.evaluate() 和 dv.tryEvaluate() 方法
这两个方法的作用实际上是执行 DQL 查询语法中的表达式。同样两个函数的区别在于执行成功与失败是否有包装一层方便用户自行处理异常情况的区分。
两个方法的第二个可选参数 context 为一个对象,用于为表达式中的变量提供值。
为了方便参考,我直接将官方支持的表达式贴出来:
# Literals
1 (number)
true/false (boolean)
"text" (text)
date(2021-04-18) (date)
dur(1 day) (duration)
[[Link]] (link)
[1, 2, 3] (list)
{ a: 1, b: 2 } (object)
# Lambdas
(x1, x2) => ... (lambda)
# References
field (directly refer to a field)
simple-field (refer to fields with spaces/punctuation in them like "Simple Field!")
a.b (if a is an object, retrieve field named 'b')
a[expr] (if a is an object or array, retrieve field with name specified by expression 'expr')
f(a, b, ...) (call a function called `f` on arguments a, b, ...)
# Arithmetic
a + b (addition)
a - b (subtraction)
a * b (multiplication)
a / b (division)
a % b (modulo / remainder of division)
# Comparison
a > b (check if a is greater than b)
a < b (check if a is less than b)
a = b (check if a equals b)
a != b (check if a does not equal b)
a <= b (check if a is less than or equal to b)
a >= b (check if a is greater than or equal to b)
# Strings
a + b (string concatenation)
a * num (repeat string <num> times)
# Special Operations
[[Link]].value (fetch `value` from page `Link`)
使用如下:
test:: 测试变量
```dataviewjs
dv.paragraph(dv.evaluate("x + y + z", {x: 1, y: 2, z: 3}).value) // 6
dv.paragraph(dv.evaluate("x + y + z", {x: 1, y: 2, z: 3}).successful) // true
dv.paragraph(dv.tryEvaluate("12 + val", {val: "world"})) // 12world
dv.paragraph(dv.tryEvaluate("hello + val", {val: "world"})) // -world
dv.paragraph(dv.tryEvaluate("val*3", {val: "world"})) // worldworldworld
dv.paragraph(dv.tryEvaluate("this.test")) // 测试变量
dv.paragraph(dv.tryEvaluate("length(this.file.tasks)")) // 0
dv.paragraph(dv.tryEvaluate("1 + 2 * 10")) // 21
dv.paragraph(dv.tryEvaluate("this.file.name")) // Untitled
dv.paragraph(dv.tryEvaluate("date(now)")) // 11:34 上午 - 5 25, 2024
dv.paragraph(dv.tryEvaluate("date(now) + dur(1d30m)")) // 12:06 下午 - 5 26, 2024
</code></pre>
<h2>五、文件I/O操作</h2>
I/O 操作是指输入(Input)/输出(Output)操作,通常用于读取/写入文件。在 Dataview 中我们使用 dv.io.csv(path, [origin-file]) 来解析 CSV 文件,使用 dv.io.load(path, [origin-file]) 来读取文件的内容,使用 dv.io.normalize(path, [origin-file]) 将相对路径转换成绝对路径。
<h3>1. dv.io.csv() 方法</h3>
首先我们在当前编辑的文件同目录创建一个名为 person.csv 的 CSV 文件,然后复制以下内容粘贴进去:
<pre><code class="language-csv line-numbers">姓名,性别,年龄
张三,男,20
李四,女,23
stu1,男,18
stu2,女,19
</code></pre>
现在,我们来通过 dv.io.csv() 方法读取数据,看一下读取数据后会被转换成什么样的结构。
<pre><code class="language-yaml line-numbers">```dataviewjs
const data = await dv.io.csv("person.csv")
console.log(data.array())
因为 dv.io.csv() 是一个异步方法,因此我们需要在调用方法时加上 await 关键词。数据读取后会返回一个 DataArray 结构的数据,通过前面的讲解,我们可以直接使用 array() 方法将数据输出为 JavaScript 数组的形式。
CSV 数据经过 Dataview 解析后每一行(除了表头)会转换成 {表头名: 数据值} 的格式。接下来我们来将其渲染到页面中。
```dataviewjs
const data = await dv.io.csv("person.csv")
const headers = Object.keys(data[0])
const values = data.map(item => Object.values(item))
dv.table(headers, values)
可选择参数 origin-file 的作用是指定解析文件所基于的相对目录,如果文档中存在多个同名的文件,在 path 中并没有带路径的话,默认在当前目录中查找。如果我们将第二个参数指定为 / 就会从根目录寻找。
如果指定的文件不存在,则会返回 undefined。
2. dv.io.load() 方法
这个方法用于读取文件,对于文本文件(如:Markdown, CSV, TXT 等)会直接原样输出文本内容,对于其它文件(如:PDF)可能会显示为乱码、特殊字符、转义序列、二进制表示,或者可能根本不显示这些数据,甚至抛出错误。
使用方式同 dv.io.csv(),只不过返回的数据是字符串(文本),需要自己去解析。
3. dv.io.normalize() 方法
这个方法的作用是规范路径,将不带路径目录的链接转换成基于当前 Vault 的绝对路径。
现在我们在根目录创建了一个 person.csv 文件,同时也在目录 dir1/dir2 和 dir1/dir2/dir3 中同时创建,然后来看一下使用效果:
```dataviewjs
console.log(dv.io.normalize("not-exist")) // not-exist
console.log(dv.io.normalize("not-exist", "/")) // not-exist
console.log(dv.io.normalize("not-exist.csv")) // not-exist.csv
console.log(dv.io.normalize("not-exist.csv", "/")) // not-exist.csv
console.log(dv.io.normalize("person.csv")) // dir1/dir2/dir3/person.csv
console.log(dv.io.normalize("person.csv", "/")) // person.csv
console.log(dv.io.normalize("person.csv", "not/exist/")) // person.csv
console.log(dv.io.normalize("person.csv", "dir1/dir2/")) // dir1/dir2/person.csv
从结果来看,如果不指定第二个参数会返回当前传入的第一个参数。在指定第二个参数的情况下,如果文件不存在则原样返回,如果指定的路径不存在同样如此。只有在路径和文件都正确的情况下来能得到正确的路径。
六、自定义视图
使用 dv.view(path, input) 方法来构建自己的视图,是一项挺有创造性的事情,它可以把我们介绍的知识点全部融入进来创建可复用的,可分发的功能集。
使用这个方法我们可以将 JavaScript 脚本和样式放置在一个目录中,然后将其异步加载并传入参数运行,默认名称约定为 view.js 和 view.css。
下面我们用一个问候函数来举例,更多高级的用法后续案例分析篇会重点讲解。
%% views/demo/view.js %%
```js
function greet(name) {
return dv.el('h1', `你好,${name}`, { cls: 'demo' })
}
greet(input.name)
%% views/demo/view.css %%
```css
.demo {
color: red!important;
}
```dataviewjs
await dv.view("views/demo", { name: "Dataview" })
代码中,所有传入的参数都存放在 input 对象中,样式我们使用了 !important 来提升优先级,不然会被 h1, .markdown-rendered h1 所覆盖。
七、辅助方法
我们在前面的代码中判断数组使用的是 Array.isArray() 方法,实际上官方也提供了一个同名的方法为 dv.isArray(),此外还提供了
dv.compare(a, b) 比较任意 JavaScript 值,如果 a > b 则返回 1,相等返回 0,小于则返回 -1。
dv.equal(a, b) 判断任意两个 JavaScript 值是否相等。
dv.clone(value) 深拷贝值。
dv.parse(value) 主要用于将字符串解析为链接、日期和持续时间。
举例:
```dataviewjs
const a = {a: 1, b: 2, c: [1, 2, 3, [4, [5, 6]]], d: {e: 1, f: 2}}
const b = {a: 1, b: 2, c: [1, 2, 3, [4, [5, 6]]], d: {e: 1, f: 2}}
const c = {a: 1, b: 2, c: b.c, d: {e: 1, f: 2}}
const d = {a: 1, b: 2, c: b.c, d: 5}
const e = dv.clone(a)
console.log(dv.isArray(a.c)) // true
console.log(dv.equal(a, b)) // true
console.log(dv.equal(a, c)) // true
console.log(dv.equal(a, d)) // false
console.log(dv.equal(a, e)) // true
console.log(dv.compare(a, b)) // 0
console.log(dv.compare(a, c)) // 0
console.log(dv.compare(a, d)) // -1
console.log(dv.parse("[[Welcome]]")) // Link {path: 'Welcome', display: undefined, subpath: undefined, embed: false, type: 'file'}
console.log(dv.parse("2024-05-25")) // DateTime {ts: 1716566400000, _zone: SystemZone, loc: Locale, invalid: null, weekData: null, …}
console.log(dv.parse("1d")) // Duration {values: {…}, loc: Locale, conversionAccuracy: 'casual', invalid: null, matrix: {…}, …}