- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
初级篇主要涉及一些比较简单的查询操作,适用于初学者练手,主要聚焦在 DQL 查询上以及基础的 JavaScript API 查询操作。
一、内联查询
内联查询适合于不需要作过多逻辑判断的属性查询,不需要指定代码块,可以在页面正文中任意位置插入查询语句。下面是 DQL 和 JavaScript API 两种语法示例。
DQL 内联查询示例:
topic:: basic inline queries
description:: Showcase basic syntax of DQL and JS Inline Queries
创建时间:`= this.file.ctime` %% 2024-05-13 11:05:56 %%
修改时间:`= this.file.mtime` %% 2024-05-15 12:05:44 %%
标签:`= this.tags` %% Blog, Dataview, Obsidian %%
内联字段查询:`= this.topic` %% basic inline queries %%
文本截取:`= truncate(this.description, 20, "...")` %% Showcase basic synt… %%
条件判断:`= choice(contains(this, "topic"), "Set", "Missing!")` %% Set %%
获取带有特殊字符的链接访问失败:`= [[博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言]].file.ctime` %% - %%
需要调整为:`= link("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.ctime` %% 2024-05-06 11:05:12 %%
文章包含的链接数量:`= length(link("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.outlinks)` %% 27 %%
除图片以外的链接数量:`= length(filter(link("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.outlinks, (x) => !meta(x).embed))` %% 2 %%
现在时间:`= date(now)` %% 2024-05-15 16:05:24 %%
持续时间:`= dur(1mo2d)` %% 1个月、2天 %%
格式化时间:`= dateformat(date(now), "M'月'dd'号'")` %% 5月15号 %%
JavaScript API 示例:
创建时间:`$= dv.current().file.ctime` %% 2024-05-13 11:05:56 %%
修改时间:`$= dv.current().file.mtime` %% 2024-05-15 12:05:44 %%
标签:`$= dv.current().file.tags` %% Blog, Dataview, Obsidian %%
内联字段查询:`$= dv.current().topic` %% basic inline queries %%
文本截取 `$= dv.func.truncate(dv.current().description, 20, "…")` %% Showcase basic synt… %%
文本截取:`$= dv.evaluate("truncate(this.description, 20, \"…\")").value` %% Showcase basic synt… %%
或者:`$= dv.tryEvaluate("truncate(this.description, 20, \"…\")")` %% Showcase basic synt… %%
条件判断:`$= dv.current().topic ? 'Set' : 'Missing!'` %% Set %%
获取文件创建时间:`$= dv.page("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.ctime` %% - %%
文章包含的链接数量:`$= dv.page("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.outlinks.length` %% 27 %%
除图片以外的链接数量:`$= dv.page("博客/Obsidian/Obsidian 达人成长之路 #1:使用终极工具 Dataview 释放笔记库的潜力 · DQL查询语言").file.outlinks.where(link => !link.embed).length` %% 2 %%
现在时间:`$= dv.date('now')` %% 2024-05-15 16:05:24 %%
持续时间:`$= dv.duration('1mo2d')` %% 1个月、2天 %%
格式化时间:`$= dv.date('now').toFormat("M'月'dd'号'")` %% 5月15号 %%
[!Tip] 使用内联 API 查询出来的标签在结果显示上和内联 DQL 的结果略有不同,前者是可交互的结果,后者为纯文本。
有没有发现在 API 中没有对应的
truncate()函数使用(骗人的:所有 DQL 查询语句能用的函数都在dv.func对象中,这里就是dv.func.truncate()),但是我们还可以dv.evalute()或者dv.tryEvaluate()函数在 API 中执行 DQL 查询。[!Warning] 注意
在文件名不要包含#符号,在使用链接时会被错误的识别为标签或者页面标题。
二、在查询结果中显示图片
在 Obsidian 中,[网站名称](网页地址) 用于插入网页链接, 用于嵌入图片(这里也可以是其它媒体,如音频、视频等),图片进一步还能指定宽度,语法为 。
图片的地址除了网页地址外,也可能为本地图片,语法为 ![[图片名称.后缀]],在 YAML 中为 "[[图片名称.后缀]]"。在使用 DQL 查询语法获取图片地址时就需要对两种类型作区分。
现在我们在 Front Matter 中添加一个属性 cover-img,其值为图片的链接数组。然后,我们来看一下如何在文档中显示图片:
---
cover-img:
- https://images-na.ssl-images-amazon.com/images/S/compressed.photo.goodreads.com/books/1546512443i/43451211.jpg
- "[[Pasted image 20240529150343.png]]"
---
`= ""`
`= "!" + this.cover-img[1]`
`= embed(link(this.cover-img[1], "50"))`
```dataview
TABLE WITHOUT ID map(cover-img, (img) => choice(typeof(img)="link", embed(link(img, "50")), "")) AS 图片
WHERE file = this.file
</code></pre>
上面的示例中,我们分别使用了 3 种方式来展示图片:
<ol>
<li>使用 <code></code> 的方式,这是 URL 图片地址显示方式。</li>
<li>使用 <code>![[xx.xx]]</code> 的方式,这种方式虽然简单,但是不能指定链接图片宽度,灵活度不够。</li>
<li>使用 <code>![[xx.xx|xx]]</code> 的方式,这是链接的推荐显示方式,需要调用 <code>embed()</code> 和 <code>link()</code> 函数来实现。</li>
</ol>
处理 Obsidian 内部图片链接时,我们利用 <code>link()</code> 函数的第二个参数来指定图片的宽度,实际上它是用于指定链接别名的,这里刚好利用其发挥额外作用了。
<blockquote>
[!Tip] 不要像上面示例中那样在 YAML 中放入链接,如果必须放需要加上双引号才能正确读取出来,否则被识别成数组。但是又衍生出另一个问题,文档属性区域会显示一个警告图标,提示:未匹配到类型,建议使用文本。
</blockquote>
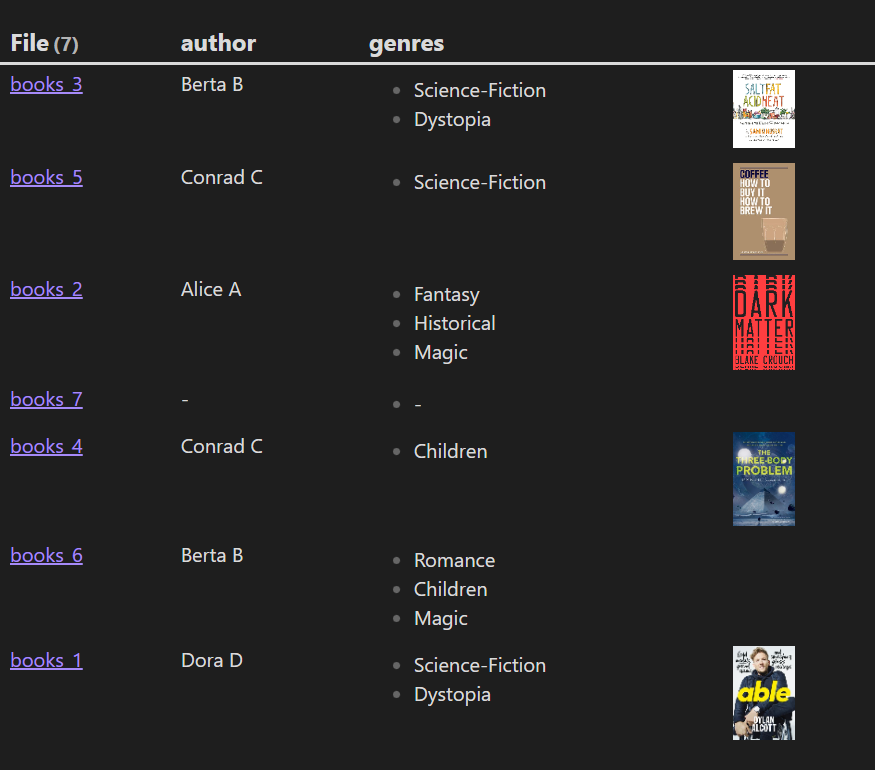
下面我们来看一下在现实场景中的应用:
```js
TABLE author, genres, EmbededCoverImg as ""
FROM "10 Example Data/books"
FLATTEN choice(typeof(cover-img)="link",
embed(link(meta(
choice(
typeof(cover-img)="link",
cover-img, this.file.link
)
).path, "50")), "") AS EmbededCoverImg
```
结果:
 下面现给出一个 API 实现方式参考:
下面现给出一个 API 实现方式参考:
dv.table(["File", "Author", "Genres", ""], dv.pages('"10 Example Data/books"')
.map(p => {
let img;
if (!p['cover-img']) {
img = ''
} else if (dv.func.typeof(p['cover-img']) === 'link') {
img = dv.fileLink(p['cover-img'].path, true, '50')
} else {
img = ``
}
return [p.file.link, p.author, p.genres, img]
}))
代码中 dv.func.typeof() 方法同 DQL 查询语句中的函数 typeof()。
三、数据分组
数组分组适用于数据具有一对多或多对多的关系,例如一个作者对应多本书籍,那么我们在查询数据时就可以按作者去分组。
在使用 DQL 查询语言 GROUP BY 时,需要明确一点的是,我们经过分组后的数据是保存在固定变量 rows 中的,这是一组数据,而非单一数据。例如在 TABLE 中没有分组时取文件链接是通过 file.link 来获取,经过分组后就需要使用 rows.file.link 来取值了。需要注意的是 rows 是一个数组,我们可以使用 rows[0] 来获取分组数据的第一项,但是我们通常不会这样做。
(1)示例一:书籍按作者分组
%% 属性样例 %%
---
author: Conrad C
---
%% 查询 %%
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
GROUP BY author AS 作者
结果:

(2)示例二:书籍按类型分组
%% 属性样例 %%
---
genres:
- Romance
- Children
- Magic
---
%% 查询 %%
TABLE rows.file.link AS 书籍
FROM "10 Example Data/books"
FLATTEN genres
GROUP BY genres AS 类别
结果:
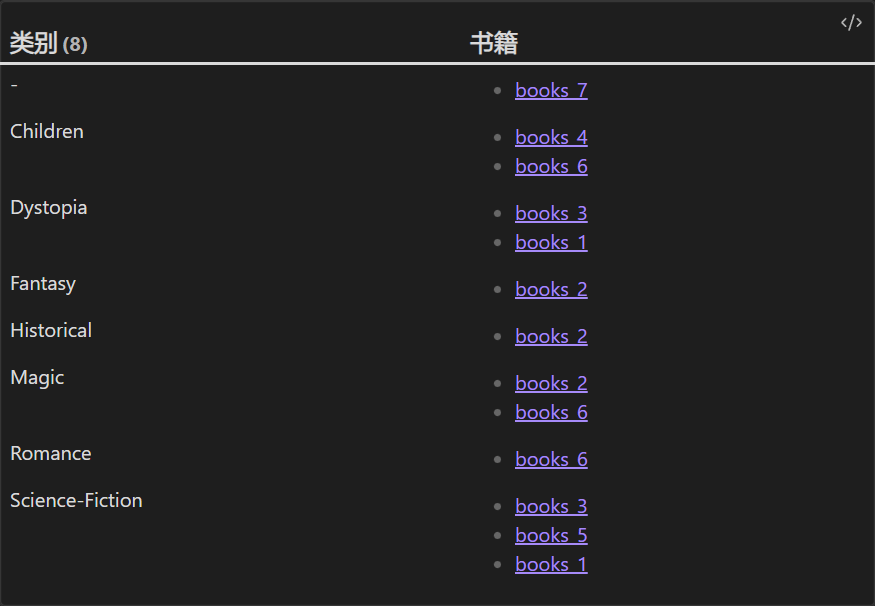
[!Tip] 这里需要注意的是 FLATTEN 语句很关键,如果不使用将会得到一个错误的结果。原因是在原始数据中每一本书可以对应多个类别,而在按类别查询分组后,结果变成多个类别对应一本书。因此我们需要把每个类别对应上同一本书来修正数据,这样再使用分组时就符合预期了。
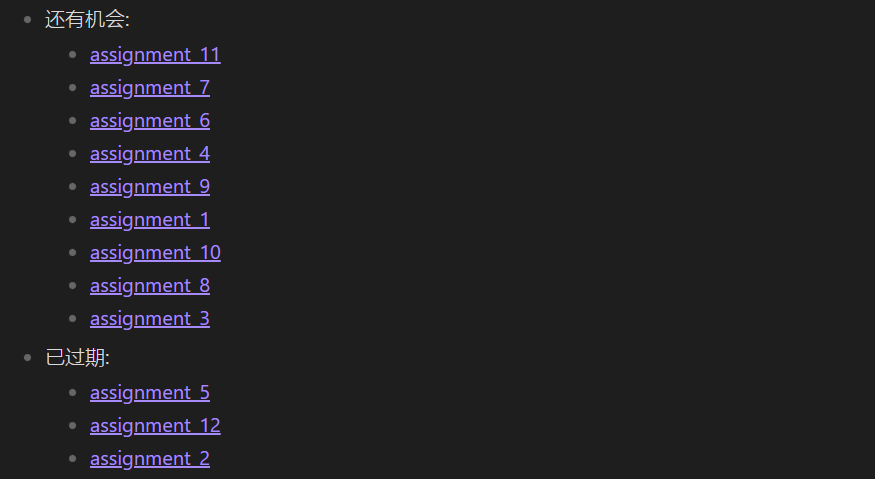
(3)示例三:根据计算结果分组
这里对任务的 due 进行分组,如果在 2022-05-12 前没有完成就视为过期。
%% 属性样例 %%
---
class: history
received: 2022-03-20
due: 2022-05-05
---
%% 查询 %%
LIST rows.file.link
FROM "10 Example Data/assignments"
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
结果:
(4)示例四:分组后的元数据
在分组章节提到了分组后的数据属性 rows,实际上使用 GROUP BY 语句后返回的是一个对象,类似于:
{
key: groupName;
rows: ArrayOfDataColumns
}
在使用时通常不会直接去显示获取 key 值,默认情况下 Dataview 会直接读取了这个字段的值作为分组名。
如【示例三】所示,可以使用 choice() 函数来执行条件判断,返回 2 个状态描述,如果我们将 LIST rows.file.link 改成 LIST,那么读取的就是 key 值,这个 key 值就是 choice() 函数执行后返回的两个状态描述文本。
在 GROUP BY 语句后面我们可以使用 AS 语句定义一个别名,例如:statusText,我们再次将列表查询语句修改成 LIST statusText,观察结果会发现会显示成类似 - 还有机会: 还有机会,这样的结果。这个时候 statusText 和 key 其实是同一个实体,如果只想显示一个分组名,或者不显示,可以使用 LIST WITHOUT ID 来达到目的。
进一步我们还可以在 LIST 语句中拼接文本(包含有效果 HTML 标签),比如给结果加上 <kbd> 标签:LIST WITHOUT ID "<kbd>" + statusText + "</kbd>",有一点需要谨记的是不能在里面使用模板字符串。
有了上面提到的技巧,对于【示例三】的结果可以进一步改成 LIST join(rows.file.link, " | ") 来减少空间占用。
对于 GROUP BY 语句我们还可以不提供分组属性,而是提供一个文本,然后只针对 rows 进行处理,比如获取其长度 length(rows),这实际上是将所有查询的数组归为一个组了。
LIST length(rows)
FROM "10 Example Data/assignments"
GROUP BY "什么也不做"
结果:

现在我们来把【示例三】根据上面提及的一些知识点进行一次改造:
- 在链接后显示
due 的具体日期值
- 对结果进行合并,显示在一个列表中
LIST join(map(rows.file, (f) => f.link + " " + f.frontmatter.due), ", ")
FROM "10 Example Data/assignments"
FLATTEN file.frontmatter.due AS path
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
结果:

进一步我们可以使用 FLATTEN 语句改造实现同样的效果,可以不用 map() 函数,直接将需要格式化显示的结果作为 rows 分组后的数据的一个属性。
LIST join(rows.desc, ", ")
FROM "10 Example Data/assignments"
FLATTEN file.link + " " + file.frontmatter.due AS desc
GROUP BY choice(due < date("2022-05-12"), "已过期", "还有机会")
四、FLATTEN 语句
FLATTEN 语句是 GROUP UP 的相反操作,但事实上它的作用不止这一点,它扮演了一个很重要的角色:声明新变量。
在介绍数据分组时有提及过 FLATTEN 语句的作用,现在我们再次以书籍数据为例子,将书籍的分类和话题查询出来:
TABLE genres, booktopics
FROM "10 Example Data/books"
结果:
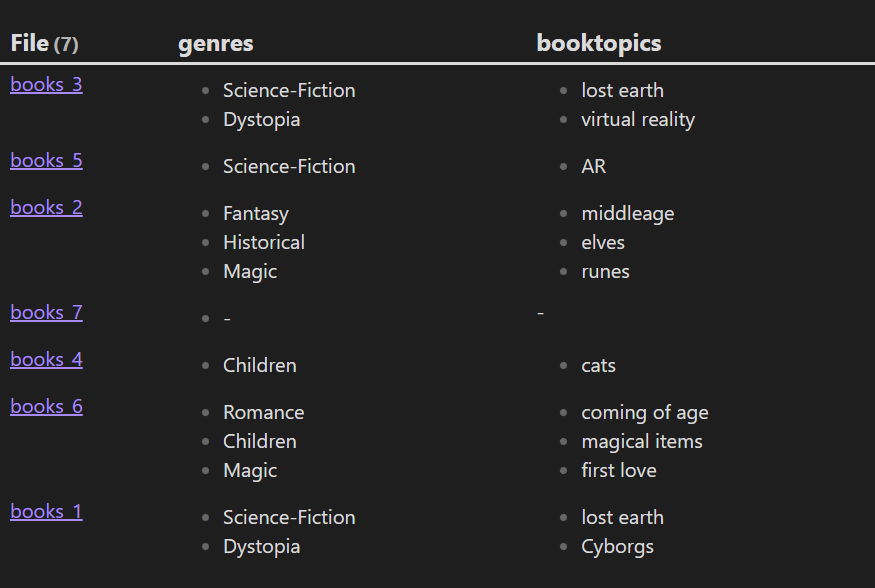
因为分类和话题其实是多对多的关系,因此我们可以使用 2 个 FLATTEN 语句对其展开成 1 维的数据列。
TABLE genres, booktopics
FROM "10 Example Data/books"
FLATTEN genres
FLATTEN booktopics
LIMIT 4
结果:
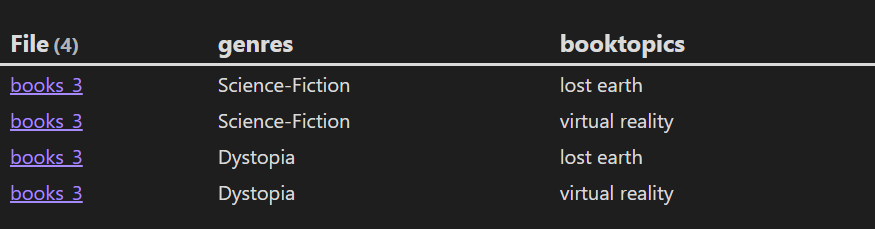
(1)声明新属性
使用 FLATTEN 语句可以将数组展开成一维数组,但对于一个不能进行展开操作的数据类型如:数字、字符串、布尔值以及对象会原样输出。利用这一特点再结合 AS 语句可以声明属性并将 FLATTEN 后面的值赋值给指定的别名。
下面我们通过 FLATTEN 语句分别声明了一个字符串 arr,一个数字 num 和一个对象 obj,对象中包含一个数组 [1, 2, 3],看一下结果如何:
TABLE WITHOUT ID num, str, obj
FLATTEN 123 AS num
FLATTEN "hello" AS str
FLATTEN {"数字": num, "字符串": str, "数组": [1,2,3]} AS obj
WHERE file = this.file
结果:

现在我们再进行一点小改变,将数组 [1, 2, 3] 单独提取出来使用 FLATTEN 语句声明一个新的属性 arr,即:FLATTEN [1, 2, 3] AS arr,然后再将 obj 修改成:FLATTEN {"数字": num, "字符串": str, "数组": arr} AS obj,结果如下:
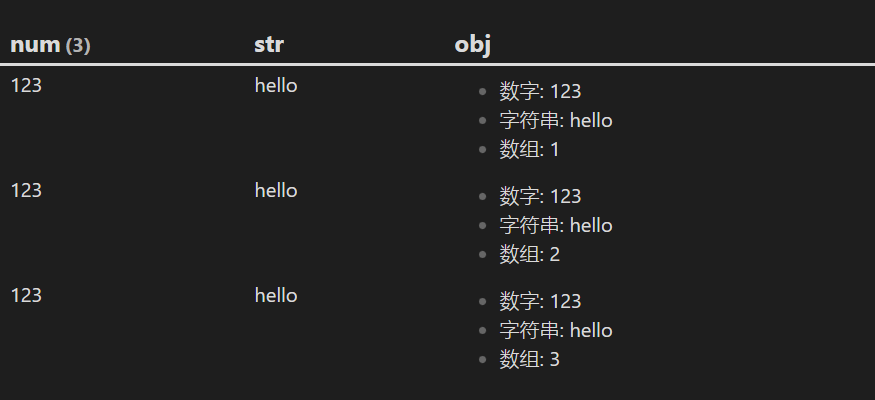
可以看到我们得到了一个完全不同的结果,这说明在使用 FLATTEN 语句声明数组时会影响结果的维数,我们可以大胆的猜测,假如使用 FLATTEN 语句声明 3 个 2 维数组,那么结果将产生 8 种结果:
table without id num1,arr1,arr2,arr3
flatten 1 as num1
flatten ["a","b"] as arr1
flatten ["c","d"] as arr2
flatten [1,2] as arr3
where file=this.file
结果:
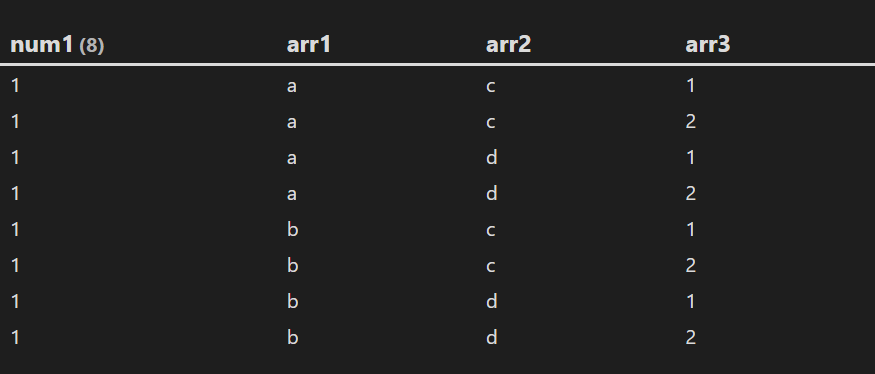
(2)处理嵌套
数据嵌套 通常指的是在数据结构或数据模型中,一个数据元素内部包含另一个或多个相同或不同类型的数据元素。这种结构使得数据能够以层次化或树状的方式组织起来,从而更好地表示复杂的数据关系。
对象嵌套对象
这种情况下,不需要额外的处理,使用和不适用 FLATTEN 语句效果是一样的。
%% 属性样例 %%
---
obj:
obj1:
obj2:
prop1: 1
prop2: 2
---
%% 查询 %%
TABLE WITHOUT ID obj
WHERE file = this.file
FLATTEN obj
结果:

有了上面的知识,下面我们来分析一个查询书籍中阅读进度不足 50% 的案例:
TABLE pagesRead, totalPages, percentage
FROM "10 Example Data/books"
FLATTEN round((pagesRead / totalPages) * 100) AS progress
WHERE progress < 50
FLATTEN progress + "%" AS percentage
结果:
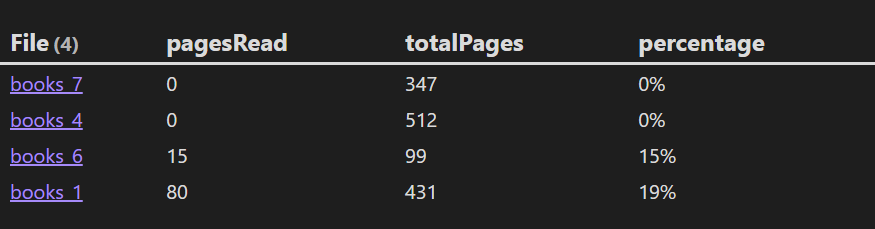
分析:
- 第一个
FLATTEN 语句用于计算阅读进度百分比。
WHERE 语句用于对进度进行条件限定。- 最后一个
FLATTEN 语句对结果进行美化。
对象和数组嵌套
这种情况下,数组项为对象或者普通类型(字符串,数字和布尔值),在对象中属性也可能为数组,相互嵌套多次。
下面是一个数组中包含了 2 个对象和一个字符,对象的属性值为数组。可以看到使用 FLATTEN 语句后对象依然保持不变。
%% 属性样例 %%
---
arr2:
- a1:
- a2
- a3
- b1:
- b2
- b3
- c1
---
%% 查询 %%
TABLE WITHOUT ID arr2
WHERE file = this.file
FLATTEN arr2
多维数组
这种情况下,数组内部嵌套数组,可能为 2 维(示例:[[1,2], [3, 4]]),3 维(示例:[[[1,2,3], [4,5, 6], [7, 8, 9]]])甚至多维,但是 FLATTEN 语句只能处理 2 维数组,如果是多维的数据,需要结合 flat(array, [depth]) 函数,通过指定 depth 来根据实际情况指定要处理的层级。
%% 属性样例 %%
---
arr3:
-
- a1
- b1
-
- c1
-
- e1
-
- f1
---
%% 查询 %%
TABLE WITHOUT ID flat(arr3, 2)
WHERE file = this.file
FLATTEN arr3
还有一种方法来实现多维数组展开,修改上面的示例,连续使用 4 次
FLATTEN arr3,得到一个展开的结果。这个结果并不能推断出原始数组是由几维展开的,在显示上也没有出现列表符号,读者可以根据需求灵活选用。
五、SORT 语句
我们通常在使用 SORT 语句时,主要是针对文件的创建日期、日记等进行排序。这里单独提出来讲解的目的在于,让大家知道怎么对一个分类属性进行手动干预排序。下面以 "10 Example Data/food" 文件中的 recipe-type 属性为例。
默认查询并根据 recipe-type 进行分组后的显示顺序为 meat , onepot 和 vegetarian,现在我们将其变成 onepot, 'meat' 和 vegetarian 的顺序,看看怎么实现:
TABLE rows.file.link
FROM "10 Example Data/food"
WHERE recipe-type
GROUP BY recipe-type
SORT choice(recipe-type="onepot", "1", choice(recipe-type="meat", "2", "3")) ASC
结果:
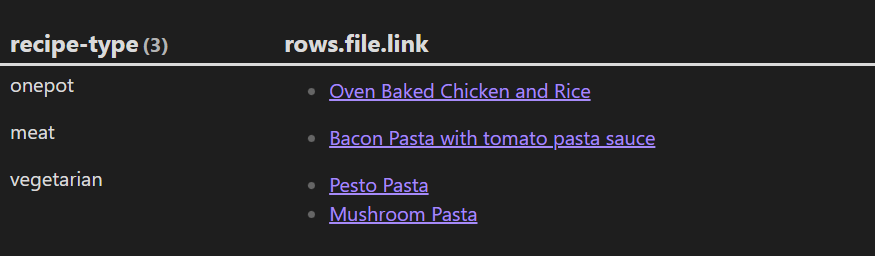
上面示例中,我们对应对的 3 个属性值的顺序调整,如果数量量很多,几十个又该如何处理呢?
我们可以用一个对象将属性作为键值,排序的权重(顺序值,如 1, 2, ...)作为值,然后以一个立即执行函数根据参数值获取顺序:
TABLE WITHOUT ID Person.name AS 姓名
FLATTEN [{name: "晓露"}, {name: "一佰度"}, {name: "周工"}, {name: "狼人头"}, {name: "腰哥"}, {name: "黑黑"}] AS Person
WHERE file = this.file
SORT default(((x) => {
"狼人头":1,
"晓露": 2
}[x])(Person.name), 99) ASC
结果:

default() 函数中第二个参数,我们只需要指定为比数据量大就可以了,后续没有指定顺序的值就会按默认的排序方式来执行。
六、根据不同条件来查询日记
在 Obsidian 中日记文件通常以 xxxx-xx-xx 的日期格式创建。我们可以通过 DQL 来精确查询完整年/月/日的日记,也可以查询指定年份、月份和具体某天的日记。下面我们以 10 Example Data/daily 中的日记数据 wake-up 为例。
[!Tip] obsidian 为日记提供了一个专门的属性 file.day 来方便我们获取以日期表示的文件名。
(1)日期精确查询
要查询一个精确的日期,只需要使用表达式来判断两个 DateView 对象是否相等。在 DQL 查询语言中可以使用一个等号来判断相等,如果要查询多个日期也可以使用逻辑运算符 OR 来添加条件。
需要注意的是,在比较时需要将目标日期使用 date() 方法封装后才能进行比较,因为 file.day 是一个 DateView 对象,不能和字符串去比较,比如:file.day = "2022-01-04" 就是一个无效表达。
```js
LIST WITHOUT ID file.link + " 起床时间:" + wake-up
WHERE file.day = date(2022-01-04) OR file.day = date(2022-01-24)
```
结果:

(2)忽略年份/月份查询
有些情况下我们并不关心是哪一年、哪一个月的日记中所记载的事项,只想知道某个月的某一天或着每年每个月 17 号自己做了些什么。
[!Tip] 如果使用 API 来查询的话还可以结合:jjonline/calendar.js: 中国农历(阴阳历)和西元阳历即公历互转JavaScript库 (github.com) 来查询每年自己农历生日的日记信息。
要查询这样的数据,需要将日期使用 dateformat() 方法进行格式化后进行比较。
按月-日查询:
LIST WITHOUT ID file.link + " 起床时间:" + wake-up
WHERE dateformat(file.day, "MM-dd") = "02-17"
按日查询:
LIST WITHOUT ID file.link + " 起床时间:" + wake-up
WHERE dateformat(file.day, "dd") = "17"
结果:
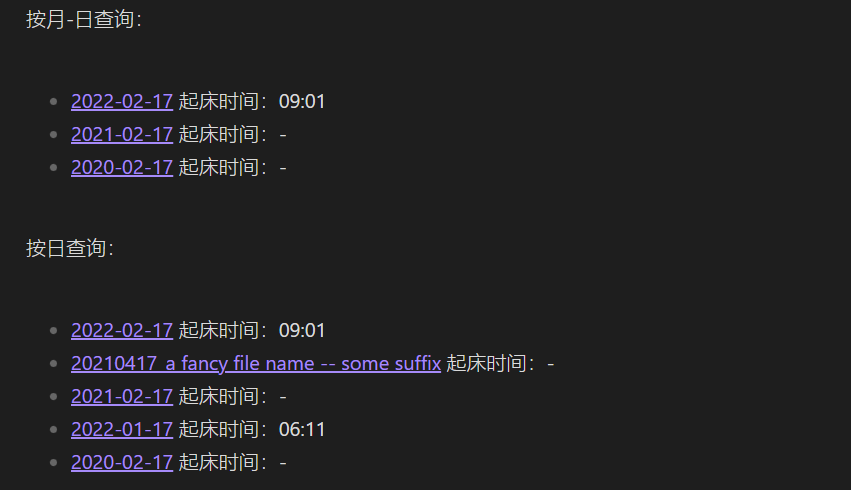
第一个查询结果因为 2020 和 2021 年日记数据中没有内联字段 wake-up,所以没有数据。第二个查询前 2 个也是同样的原因,第 4 个结果我们可以看出,只要文件面中包含符合日期的格式就会被解析出来。
(3)根据日记中特定属性查询
上面 2 个示例中我们在查询结果中显示了内联属性 wake-up,会发现有的日记并没有定义这个属性,同时在已有的数据情况下,我们还可以进一步进行过滤,例如:起床时间在 6:00 ~ 6:30 的日期。
由于在 DQL 查询语言中我们无法将 wake-up 的值读取并传入 date() 函数,所以只能采取一种不友好的方式来实现:将时间按 : 拆分后单独判断。
[!Tip] 我们无法将内联属性传 date() 函数,但是使用 FLATTEN AS 声明的日期、file.day 和 file.frontmatter.xx 的日期值还是可以传入正常解析的。
下面是两方式实现示例:
LIST WITHOUT ID file.link + " 起床时间:" + wake-up
FROM "10 Example Data/dailys"
WHERE wake-up
FLATTEN number(split(wake-up, ":")[0]) AS hour
FLATTEN number(split(wake-up, ":")[1]) AS minute
WHERE hour = 6 AND minute <= 30
const dt = dv.luxon.DateTime
const start = dt.fromObject({ hour: 6, minute: 0 })
const end = dt.fromObject({ hour: 6, minute: 30 })
dv.list(
dv.pages('"10 Example Data/dailys"')
.where(p => p["wake-up"])
.filter(p => {
const time = dt.fromFormat(p["wake-up"], "HH:mm")
return time >= start && time <= end
})
.map(p => `${p.file.link} 起床时间:${p["wake-up"]}`)
)
结果:
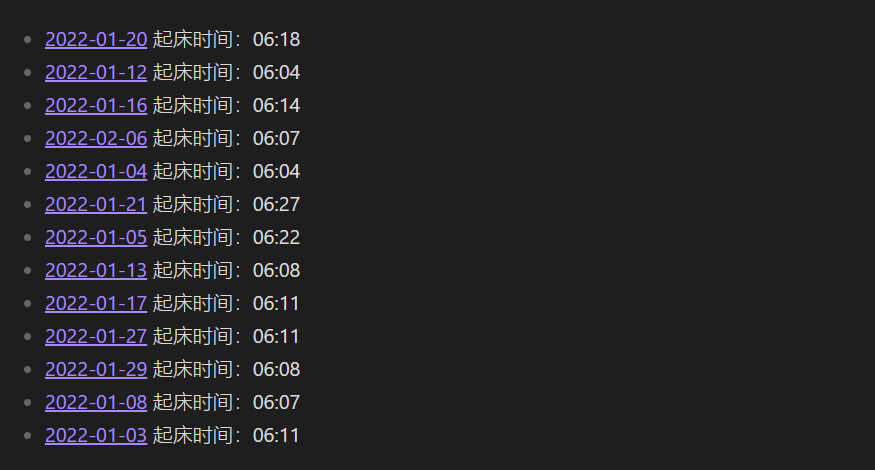
在处理时需要注意,在表示 6 点时,数据源中有少部分是 6:xx 其它为 06:xx。我们上面的代码中无须担心会被其影响,因为在使用 number() 方法时,06 会变成数字 6,而在脚本实现中 dt.fromFormat() 方法会自动处理。如果是字符串比较就需要慎重一些,将其考虑在内。
七、查询联系人的最后一次见面日期
下面是日记中和联系人的见面信息记录:
#### Appointments
My next appointment with (person:: [[AB1908]]) is on (appointment:: 2022-06-02).
Also I have an appointment at (appointment:: 2022-05-24 13:17) with (person:: [[Bob]])
现在我们来查询和每一个人的最后一次约会日期以及目前为止过去了多少天,并按降序排序(最近日期显示在前面):
TABLE WITHOUT ID
contactedPerson AS "Person",
max(rows.file.link) AS "Last contact",
min(rows.elapsedDays) + " days" AS "Elapsed days"
FROM "10 Example Data/dailys"
WHERE person
FLATTEN (date(today) - file.day).days AS elapsedDays
FLATTEN person AS contactedPerson
GROUP BY contactedPerson
SORT max(rows.file.day) DESC
结果:
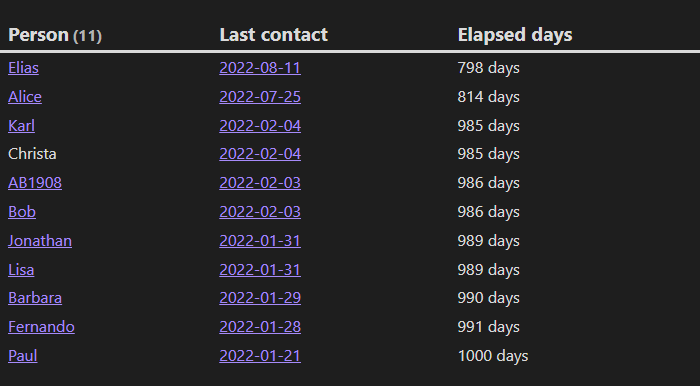
从这个示例中我们可学到一点日记小技巧:如何使用 (xx: xx) 内联字段来记录信息,并在后期进行查询。
示例中显示的是最后一次见面日期,如果要查询日记信息中第一次见面时间,可以将查询语句中的第 3 行改成 min(rows.file.link) As "First contact"。
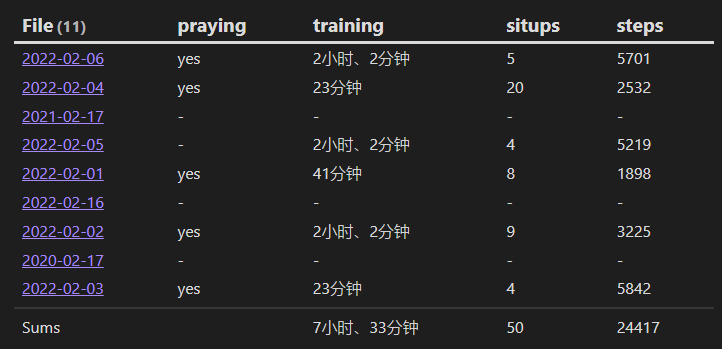
八、计算每天的醒来时长
下面这个案例中,我们查询日记数据中的 wake-up 和 go-to-sleep 行内属性,来计算出醒来时长。
TABLE wake-up, go-to-sleep, wakeTime
FROM "10 Example Data/dailys"
LIMIT 10
FLATTEN dateformat(file.day, "yyyy-MM-dd") as dt
FLATTEN date(dt + "T" + go-to-sleep) - date(dt + "T" + wake-up) as wakeTime
结果:
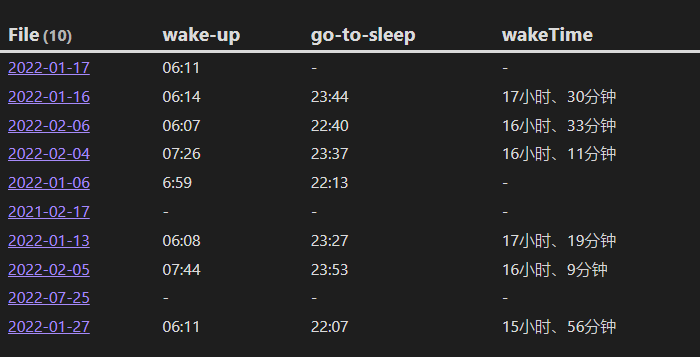
进一步阅读:Calculate waking phase with wake up and go to sleep times - Dataview Example Vault (s-blu.github.io)
九、按周显示数据
下面这个示例,我们通过指定的周数 2022-W5 查询日记中的 note 属性的值,并以本地化的时间显示星期数。
TABLE WITHOUT ID "**" + dateformat(file.day, "cccc") + "**" AS "Day" , choice(typeof(note) = "array", note, array(note)) AS "Notes"
FROM "10 Example Data/dailys"
FLATTEN "2022-W5" AS Week
WHERE string(file.day.year) = split(Week, "-W")[0] AND string(file.day.weekyear) = split(Week, "-W")[1]
SORT file.name
结果:
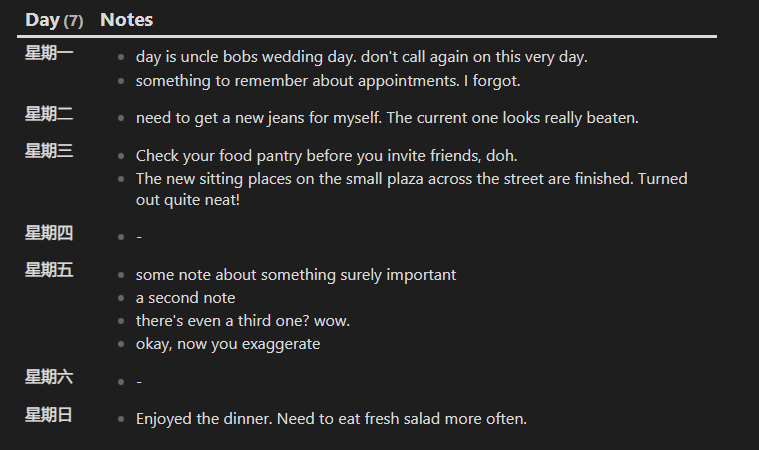
关于日期格式符可以参见:Formatting (moment.github.io)
十、查询特定标题下的任务
创建一个页面,在页面中复制以下面容:
# title 1
- [ ] task 1
- list 1
## title 2
- [x] task 2
- [ ] task 2.1
- list 2
### title 3
- [ ] task 3
- list 3
现在我们来看如何在当前页面中查询标题 title 2 下的任务。
TASK
WHERE file = this.file AND meta(section).subpath = "title 2"
结果:

[!Tip] 我们在查询中使用的 section 属性只存在于 TASK 查询中,虽然在 Dataview 中任务也是一种列表项,内部使用了 task 属性是否为 true 来判断列表为任务。但是,需要注意的是换成 LIST 查询就会出现执行错误。
进一步,如果想判断任务是否完成,还可以结合 completed 和 fullyCompleted 属性来过滤任务:WHERE file = this.file AND meta(section).subpath = "title 2" AND completed。
接下来我们来使用 API 的方式同样实现任务的查询,但在这里我们有 3 种方式来实现。
- 直接从
file.tasks 获取任务,以 dv.taskList() 输出。
- 从
file.lists 获取列表,并通过 task 属性为 true 来判断任务,以 dv.taskList() 输出。
- 接着第 2 种,但以
dv.list() 输出,同时模拟任务显示。
参考代码如下:
TASK
WHERE file = this.file AND meta(section).subpath = "title 2"
dv.taskList(
dv.current().file.tasks
.where(t => t.section.subpath === "title 2")
)
dv.taskList(
dv.current().file.lists
.where(t => t.section.subpath === "title 2" && t.task)
)
dv.list(
dv.current().file.lists
.where(t => t.section.subpath === "title 2" && t.task)
.map(t => `- [${t.checked ? "x" : " "}] ${t.text}`)
)
结果:

实现一、二都没有问题,优先采用实现一,第三种实现只是模拟,不能反向操作,对查询结果任务状态的改变不会反应到原任务。从结果截图中还可以看出第三种显示又是列表又是任务,两者叠加在一起了,其实我们可以换一种方式,使用 dv.paragraph() 来渲染,就会好看一点,就不具体展开了。
十一、合并数据到同一个表格列
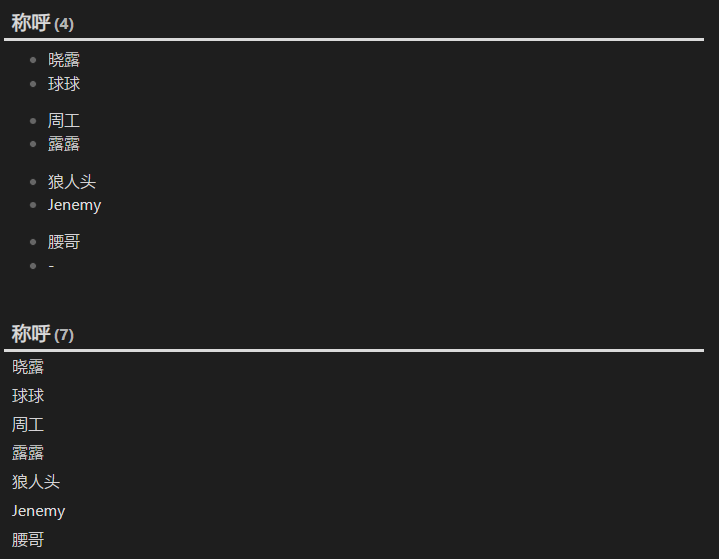
在 TABLE 查询输出时,我们可以将两个属性进行合并成一个列表进行显示。
TABLE WITHOUT ID [Person.name, Person.nickname] AS 称呼
FLATTEN [{name: "晓露", nickname: "球球"}, {name: "周工", nickname: "露露"}, {name: "狼人头", nickname: "Jenemy"}, {name: "腰哥"}] AS Person
WHERE file = this.file
如果数据中缺少其中某个属性,则会显示为 -,下面我们通过 filter() 函数来处理一下,过滤掉不存在的属性。
TABLE WITHOUT ID name AS 称呼
FLATTEN [{name: "晓露", nickname: "球球"}, {name: "周工", nickname: "露露"}, {name: "狼人头", nickname: "Jenemy"}, {name: "腰哥"}] AS Person
WHERE file = this.file
FLATTEN filter([Person.name, Person.nickname], (x) => x) AS name
对比结果:
十二、进度条
在 HTML 中有一个标签 <progress> 来渲染进度条,我们可以很容易的使用内联查询 JS 或 dv.el() 函数来实现。
pagesRead:: 42
totalPages:: 130
`$= const value = Math.round((dv.current().pagesRead / dv.current().totalPages) * 100); "<progress value='" + value + "' max='100'></progress>" + " " + value + "%"`
结果:

下面这个案例中,我们在页面中设置了两个内联字段来分别表示当前进度值和目标总数值,并根据不同的进度显示不同的图片。
wordcount:: 3900
targetcount:: 15000
const pagePath = "Add a NaNoWriMon to your vault"
const inlineWordcount = "wordcount"
const inlineTargetcount = "targetcount"
const name = "Bulba"
const images = ["Pokémon-Icon_001.png", "Pokémon-Icon_002.png", "Pokémon-Icon_003.png"]
const page = dv.page(pagePath)
let image = images[0]
const percentage = Math.round(page[inlineWordcount] / page[inlineTargetcount] * 100)
if (percentage > 33 && percentage < 66) {
image = images[1]
} else if (percentage > 66) {
image = images[2]
}
const attachments = this.app.vault.getConfig("attachmentFolderPath")
const basePath = this.app.vault.adapter.basePath
const html = `<div class="monwrapper" style="display:flex;align-items:center;">
<img src="${basePath}/${attachments}/${image}" class="mon" style="margin-right:10px;"></img>
<div>
<div class="monname">${name}</div>
<div class="progressbar"><progress max="100" value="${percentage}"></progress> Lv. ${percentage}</div></div>
</div>`;
dv.el("div", html)
结果:
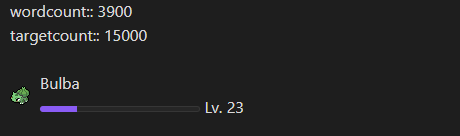
代码中 this.app.vault.getConfig("attachmentFolderPath") 用于获取我们配置的附件文件夹路径。getConfig() 方法也可以读取 .obsidian/app.json 中的其它配置。this.app.vault.adapter.basePath 用于获取当前笔记在操作系统中的路径,如:D:\Test_Note。
[!Tip] 如果在 Mac 中发现图片并没有成功显示,控制台报 net::ERR_FILE_NOT_FOUND 错误。正确的使用姿势是在原有的路径上添加 file:/// 前缀,即:<img src="file://${basePath}/${attachments}/${image}" />。
下面我们再看一个复杂的进度条案例。
查询项目数据,并对每个目标及包含的项目的完成情况进行可视化显示。
const DQL = await dv.tryQuery(`
TABLE WITHOUT ID
G AS Goals,
rows.OUT,
map(rows, (r) => r.Lt),
map(rows, (r) => r.Lc),
map(rows, (r) => "<progress style='width:80px;' value='" + (r.Lc/r.Lt)*100 + "' max='100'></progress>" + " <span style='font-size:smaller;color:var(--text-muted)'>" + round((r.Lc/r.Lt)*100) + "%</span>")
FROM #goal
FLATTEN file.outlinks AS OUT
WHERE OUT.file.tasks
FLATTEN length(OUT.file.tasks) AS Lt
FLATTEN length(filter(OUT.file.tasks, (p) => p.completed)) AS Lc
GROUP BY file.link AS G
SORT G ASC
`)
const globalValues = DQL.values
.map(row => {
console.log(row)
return [
row[0], //Goals Link
removeBulletpoints(row[1]), // Project links
removeBulletpoints(row[4]), // progress bars
"<progress value='" + sumUp(row[3])/sumUp(row[2]) * 100
+ "' max='100'></progress><br><span style='font-size:smaller;'>"
+ Math.round(sumUp(row[3])/sumUp(row[2]) * 100) + "% completed</span>"
]})
dv.table(["Goals", "Projects", "Progress", "Goal Progress"], globalValues);
function removeBulletpoints(array) {
return array.join("<br>")
}
function sumUp(val) {
return val.reduce((acc, val) => acc + val, 0)
}
结果:
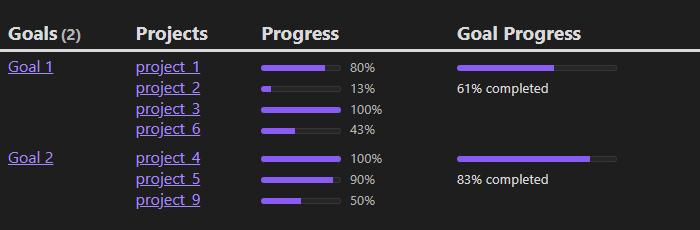
这个例子中查询的数据源有 2 个目标 Goal 1 和 Goal 2,两个文件中分别外链了 Project 1~9,并且都标记了 #goal 标签。所以 DQL 查询语句先通过标签来获取 2 个目标文件,然后通过外链获取所有项目中的任务,并根据每个任务文件中的任务数和完成数来生成进度条。
例子中的 removeBulletpoints() 函数去除 Bullet 的方式让我们又 Get 到了新技能:如何去掉列表丑陋的小点点。
name:: 标题1
name:: 标题2
name:: 标题3
TABLE WITHOUT ID name AS 姓名
where file = this.file
TABLE WITHOUT ID join(name, "<br>") AS 姓名
where file = this.file
结果: