- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
中级篇主要介绍一些复合操作以及 dv.view() 的使用。
一、链接查询
Obsidian 作为双链笔记应用中的佼佼者,提供了强大的链接支持。而我们作为使用者,能够熟练掌握并应用链接,同时在 Dataview 中根据需求写出相应的查询语句或代码,更是如虎添翼。
链接在 Obsidian 中可以理解成一个文件(主要是指 Markdown 文件)的抽象,查询链接实际就是在查询一个文件名或者其内容。
如果初学读者没有阅读过系列文章前 2 篇,不了解 Obsidian 中的链接建议先去补充一下基础知识。这里我也简单汇总一下链接的知识点。
- 链接以
[[xxx]]的语法引入文档中,如果在前面加感叹号,即:![[xxx]],则表示将链接的内容嵌入文档中。 - 我们将当前文档引入的链接称之为出链(Outgoing links),如果有其它文档引用了当前文档,则将其它文档称之为外链(Backlinks)。
- 链接有 4 种方式:
[[xxx]]|[[xxx#x]|[[xxx#^x]和[[xxx#^x|x],分别表示链接到文档、标题、段落(又叫块)以及使用显示别名。
1. 查询不存在的引用链接
在 Obsidian 中使用 [[xxx]] 引用链接时,不一定要求链接指向的文件存在于库中,因此,会存在大量空链接。页面中引用的链接存放在 file.outlinks 属性中,我们可以读取其中的值来进一步判断链接是否存在。
TABLE WITHOUT ID key AS "unresolved link", rows.file.link AS "referencing file"
FROM "10 Example Data"
FLATTEN file.outlinks as outlinks
WHERE !(outlinks.file) AND !(contains(meta(outlinks).path, "/"))
GROUP BY outlinks
上面代码 !(outlinks.file) 用于判断 [[]] 的情况,对于 [[xxx]] 通过 meta() 函数得到的链接描述信息中 path 值为 xxx,而有效的链接路径为:xx/xx/xxx.md 的形式,因此示例中判断路径是否包含 / 是可以排除这种无效链接的。
在 Dataview 提供的 API 中,我们使用 dv.app.metadataCache 来获取 Obsidian API 中链接文本对象,这个对象有两个属性,分别为:
resolvedLinks: Record<string, Record<string, number>>包含所有已解析的链接。unresolvedLinks: Record<string, Record<string, number>>包含所有未解析的链接。
假如文档 测试.md 包含一个不存在的 [[xxx]] 链接,那么在 unresolvedLinks 中表示如下:
{
"测试.md": {
"xx": 1
}
}
xx 代表链接名称,它的值是一个数字,表示在当前文档中出现的次数。
下面我们来遍历输出当前文档中不存在的链接:
dv.list(Object.keys(dv.app.metadataCache.unresolvedLinks[dv.current().file.path]))
如果要查询库中所有不存在的链接,将遍历方式修改一下:
dv.list(new Set(Object.values(dv.app.metadataCache.unresolvedLinks).flatMap(l => Object.keys(l)).sort()).values())
这里需要使用 Set() 来去重,因为同一个链接可能在不同的页面引用多次。
上面我们只是将仓库中所有不存在的链接遍历并以列表的形式显示出来了,现在我们进一步将每一个链接所包含的文件列举出来:
const unresolvedLinksMap = dv.app.metadataCache.unresolvedLinks
const res = {}
for (let page in unresolvedLinksMap) { // page 为文件路径
const unresolved = Object.keys(unresolvedLinksMap[page])
if (unresolved.length === 0) continue
for (let link of unresolved) { // file 为链接名
if (!res[link]) res[link] = {link, usages: []}
res[link].usages.push(dv.fileLink(page))
}
}
dv.table(["Unresolved Link", "Contained in"], Object.values(res).map(l => [dv.fileLink(l.link), l.usages]))
结果部分截图:
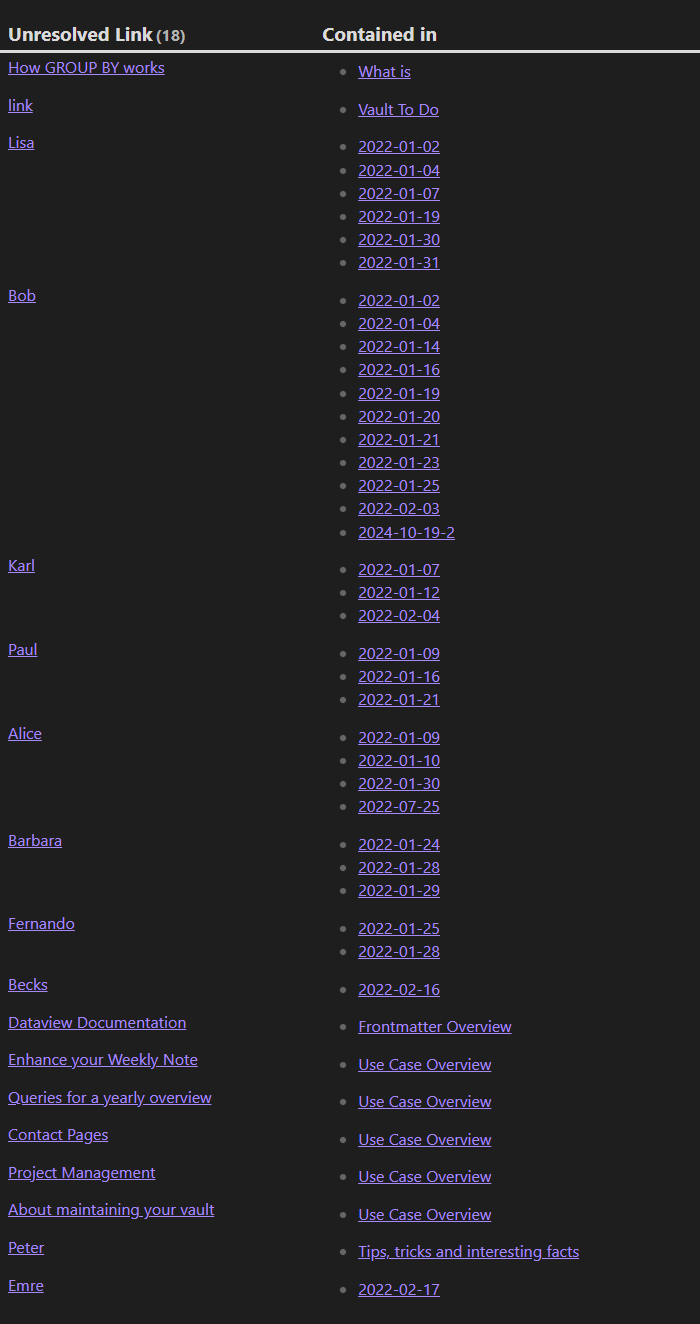
进一步阅读:List non existing, linked pages – Dataview Example Vault (s-blu.github.io)
2. 查询所有未被使用的附件
在 Obsidian 中文档是以 Markdown 格式保存的,所以其它文档类型我们都可以视作附件。当然这也不是绝对的,如果安装的插件自带了特定格式的源文件我们不能将其作附件。
要获得所有文件列表,我们需要用到 app.vault.getFiles() 方法,并过滤掉所有 Markdown 文件得到附件列表。同时,查询所有文档中的外链,过滤掉指向 Markdown 文档的链接。如果非 Markdown 文档的链接列表中包含附件列表中的文件,则说明附件已使用。
注意:这里的 app 是一个全局属性,可以在 Dataviewjs 代码块直接访问。
const allNonMdFiles = app.vault.getFiles().filter(f => f.extension !== "md")
const allNonMdOutlinks = dv.pages().file.outlinks.path.filter(link => !link.endsWith(".md"))
const notReferenced = allNonMdFiles.filter(f => !allNonMdOutlinks.includes(f.path))
dv.list(dv.array(notReferenced).map(link => dv.fileLink(link.path)))
结果部分截图:
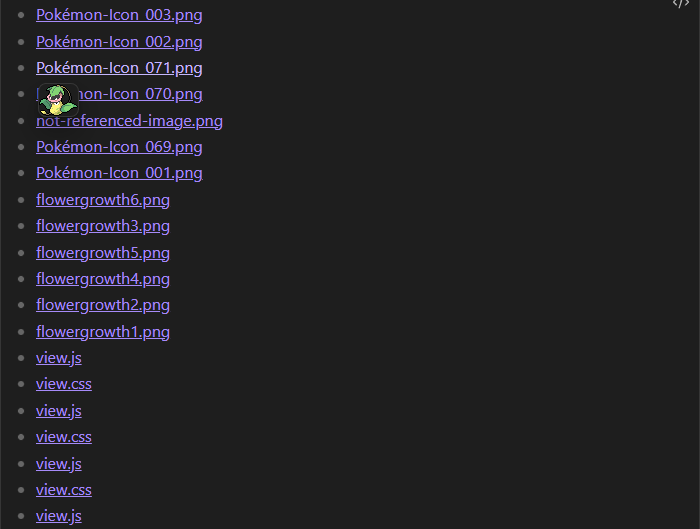
如果要指定多个非附件文档后缀,比如截图中的 .loom 文件后缀,可以将第一行代码中的过滤语句修改成:['md', 'loom'].includes(file.extension)。
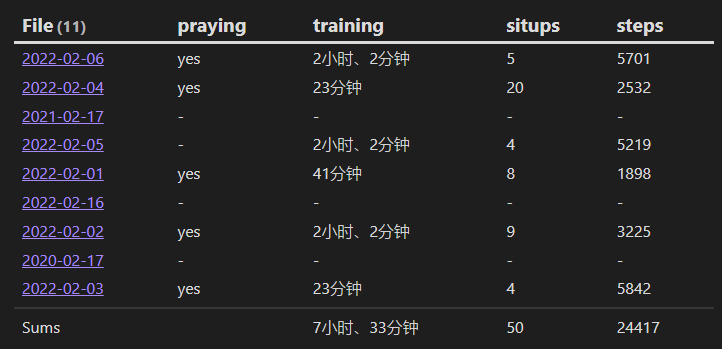
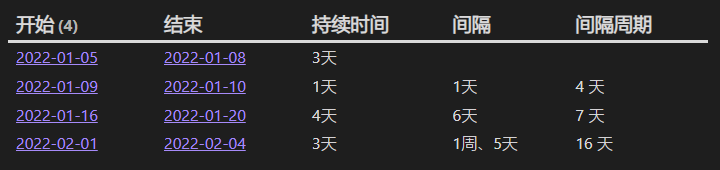
二、计算连续头痛的周期和持续时间
通过 YAML 中的属性 wellbeing.pain-type 是否包含 head 来判断当日是否有头痛记录,然后计算持续的天数以及上一次的间隔周期。
const dt = dv.luxon.DateTime
const dur = dv.luxon.Duration
// 返回一个由每个页面的前一天的页面(如果存在)组成的集合,并按日期降序排序。需要注意的是,并不是所有日期都有前一天的数据。
let startDates = dv.pages('"10 Example Data/dailys"')
.mutate(p => p.previousDay = dv.page(dt.fromMillis(p.file.day - dv.duration("1d"))
.toFormat('yyyy-MM-dd')))
.sort(p => p.file.name)
// 结束日期的数据:当日没有记录数据,但前一天有记录。
const endDates = dv.array(dv.clone(startDates)[0]).where(p => !checkCriteria(p) && checkCriteria(p.previousDay))
// 开始日期的数据:当日有记录数据,但前一天无记录。
startDates = startDates.where(p => checkCriteria(p) && !checkCriteria(p.previousDay))
// 存放周期数据
const cycles = []
for (let i = 0; i < endDates.length; i++) {
cycles.push([ startDates[i].file.link,
endDates[i].file.link,
dur.fromMillis(endDates[i].file.day - startDates[i].file.day),
i === 0 ? '' : dur.fromMillis(startDates[i].file.day - endDates[i-1]?.file.day),
i === 0 ? '' : dur.fromMillis(startDates[i].file.day - startDates[i-1]?.file.day).toFormat("d '天'")
])
}
// 输出为表格
dv.table(["开始", "结束", "持续时间", "间隔", "间隔周期"], cycles)
function checkCriteria(p) {
return p && p.wellbeing && (p.wellbeing["pain-type"] || []).contains("head")
}
结果:
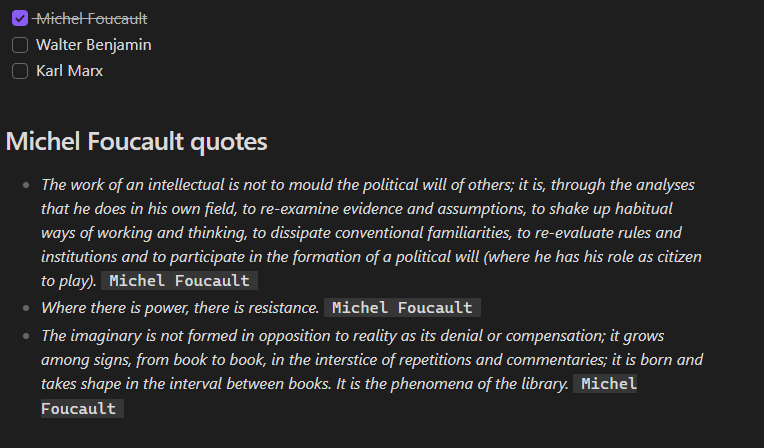
三、根据复选框动态显示内容
当前页面中以作者名为任务名,当任务完成时自动去查询在日记中有引用自该作者的语录,当取消完成时,自动移除相关语录信息。
- [x] Michel Foucault
- [ ] Walter Benjamin
- [ ] Karl Marx
const checklist = dv.current().file.tasks.where(t => t.completed)
const authors = ["Michel Foucault", "Walter Benjamin", "Karl Marx"]
// 这里将原来代码中的 3 段代码用一个遍历重写了
authors.forEach(author => {
if (isActive(author)) {
dv.header(2, `${author} quotes`)
dv.list(dv.pages('"10 Example Data/dailys"').flatMap(p => p.file.lists)
.where(l => l.author == author)
.text)
}
})
function isActive(name) {
// 原代码使用 `t.text == name` 来判断并不准确
// 因为我们安装了 tasks 插件后,任务完成会自动加上表情符号和完成日期。
return checklist.where(t => t.text.contains(name))[0]
}
结果:
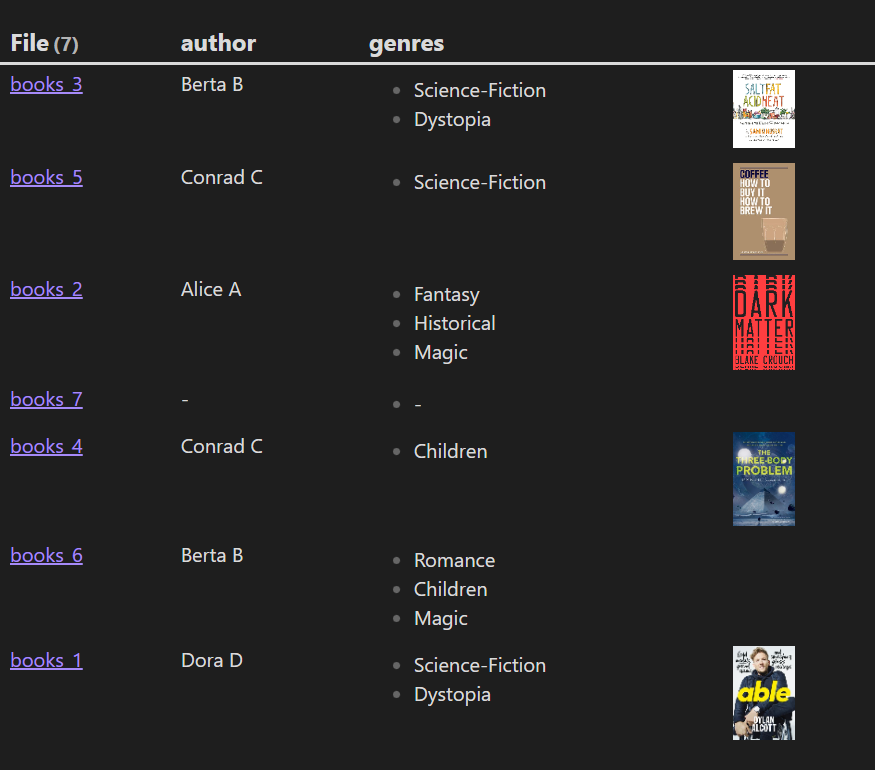
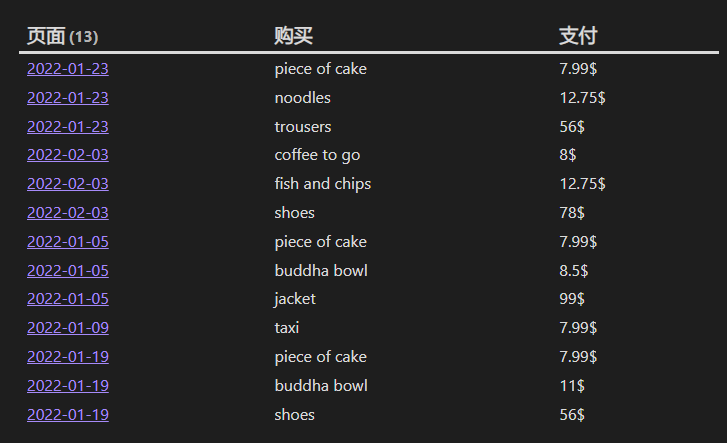
四、按照文件中的顺序对重复的元数据字段进行分组
这个案例对日记中以下数据中的 bought 进行查询并显示出对应的 paid 数据。
#### Money spent
bought:: piece of cake
paid:: 7.99$
bought:: buddha bowl
paid:: 8.5$
bought:: jacket
paid:: 99$
从数据可以看出 bought 和 paid 在页面中是重复出现,这在 Obsidian 中将会被解析成 bought: ['piece of cake', 'buddha bowl', 'jacket'] 和 paid: ['7.99$', '8.5$', '99$']。
const pages = dv.pages('"10 Example Data/dailys"').where(p => p.bought)
const groupedValues = [];
for (let page of pages) {
const length = Array.isArray(page.bought) ? page.bought.length : 1;
for (let i = 0; i < length; i++) {
groupedValues.push([
page.file.link,
getValue(page, 'bought', i),
getValue(page, 'paid', i),
]);
}
}
dv.table(["页面", "购买", "支付"], groupedValues)
function getValue(page, key, i) {
return page[key] && Array.isArray(page[key]) ? page[key][i] : page[key];
}
结果:
代码优化:
const pages = dv.pages('"10 Example Data/dailys"').where(p => p.bought)
.sort(p => p.file.name)
const groupedValues = [];
for (let page of pages) {
const length = Array.isArray(page.bought) ? page.bought.length : 1;
for (let i = 0; i < length; i++) {
groupedValues.push([
page.file.link,
getValue(page, 'bought', i),
getValue(page, 'paid', i),
]);
}
}
// 重组数据
const newPages = groupedValues.map(g => {
return {
link: g[0],
bought: g[1],
paid: g[2],
}
})
// 按 bought 进行分组
const newGroupedValues = dv.array(newPages)
.groupBy(p => p.bought)
.flatMap(g => g.rows)
dv.table(
["购买", "支付", "页面"],
newGroupedValues.flatMap((g, i, arr) => {
let j = 0; // 用于判断 bought 是否连续
// 找到连续的 bought
if (i > 0 && g.bought !== arr[i - 1].bought) {
j = i;
}
// 计算连续的数量
while (j < arr.length - 1 && arr[j+1].bought === g.bought) {
j++;
}
if (j > i) {
return Array(j - i + 1).fill(0).map((_, k) => {
if (k === 0) {
return [g.bought, g.paid, g.link]
} else {
// 相同名字显示 --
return ['--', arr[i + k].paid, arr[i + k].link]
}
})
}
// 单个 bought
if (i === j && g.bought !== arr[i - 1].bought) {
return [[g.bought, g.paid, g.link]]
}
})
)
function getValue(page, key, i) {
return page[key] && Array.isArray(page[key]) ? page[key][i] : page[key];
}
上述代码是在 groupedValues 的基础上对数据进行了一次重映射,然后使用 dv.array() 方法将普通的 JavaScript 数组转换成 DataArray<T> 类型,然后使用其 groupBy() 方法按 bought 字段进行分组,然后使用 flatMap() 映射返回 rows 的值。
[Tips] 使用
groupBy()分组后返回一个包含key和rows的对象,其中key为分组名称,rows是分组后的数据。
flatMap() 方法是一个很重要的函数,关于其用法可自行去脑补,后面处理分组数据部分写出来后,思索着应该还有更简单的实现。与是,作者又双叒叕熬夜想了想,终于以 2 个 flatMap() 方法成功破局,一行代码暴击(不追求代码可读性为前提):
const pages = dv.pages('"10 Example Data/dailys"').where(p => p.bought)
.sort(p => p.file.name)
const groupedValues = [];
for (let page of pages) {
const length = Array.isArray(page.bought) ? page.bought.length : 1;
for (let i = 0; i < length; i++) {
groupedValues.push([
page.file.link,
getValue(page, 'bought', i),
getValue(page, 'paid', i),
]);
}
}
// 重组数据
const newPages = groupedValues.map(g => {
return {
link: g[0],
bought: g[1],
paid: g[2],
}
})
// 按 bought 进行分组
const newGroupedValues = dv.array(newPages)
.groupBy(p => p.bought)
dv.table(
["购买", "支付", "页面"],
newGroupedValues.flatMap((g, i, arr) =>
g.rows.flatMap((r, i, arr) => {
if (i === 0) {
return [[g.key, r.paid, r.link]]
} else {
return [['--', r.paid, r.link]]
}
})
)
)
function getValue(page, key, i) {
return page[key] && Array.isArray(page[key]) ? page[key][i] : page[key];
}
最后,如果你脑子又一转,在数据很多的情况下,是否可以将每个分组拆解出来单独显示呢?也就是说多个表格单独显示,像下面这样:
这必需安排起,只需要将上面的示例中的 dv.table() 部分改成下面的代码即可:
for (let g of newGroupedValues) {
dv.span('- ' + g.key)
dv.table(
["页面", "支付"],
g.rows.map(r => [r.link, r.paid])
)
}
五、显示标签云
这个案例中我们将仓库中所有标签按引用次数,设定不同的权重并使用 dv.view() 来加载脚本和样式。
%% 查询代码 %%
```dataviewjs
await dv.view("00 Meta/dataview_views/tagcloud",
{
values: dv.pages('"10 Example Data/dailys"').where(p => p.person).person
})
</code></pre>
%% 脚本 %%
<pre><code class="language-js line-numbers">dv.container.className += ' tagcloud';
const uniqueValues = {};
input.values.forEach(val => {
if (uniqueValues[val]) {
uniqueValues[val]++;
} else {
uniqueValues[val] = 1;
}
});
const quantities = Array.from(new Set(Object.values(uniqueValues).sort((a, b) => b - a)));
const sizeClassMap = {
small: 1,
medium: 2,
big: 3,
};
if (quantities.length > 3) {
const third = Math.floor(quantities.length / 3);
sizeClassMap.small = quantities[quantities.length - third];
sizeClassMap.medium = quantities[third * 2];
sizeClassMap.big = quantities[third];
}
Object.keys(uniqueValues).forEach(t => {
const sizeClass =
uniqueValues[t] <= sizeClassMap.small ? 'small' : uniqueValues[t] <= sizeClassMap.medium ? 'medium' : 'big';
dv.span(t, { cls: 'cloud-item ' + sizeClass });
});
%% 样式 %%
```css
.cloud-item {
display: inline-block;
padding: 4px;
margin: 4px;
border-radius: 4px;
background: rgba(221, 221, 221, 0.2);
}
.cloud-item.small {
font-size: 0.85em;
}
.cloud-item.medium {
font-size: 1.1em;
}
.cloud-item.big {
font-size: 1.4em;
}
结果:

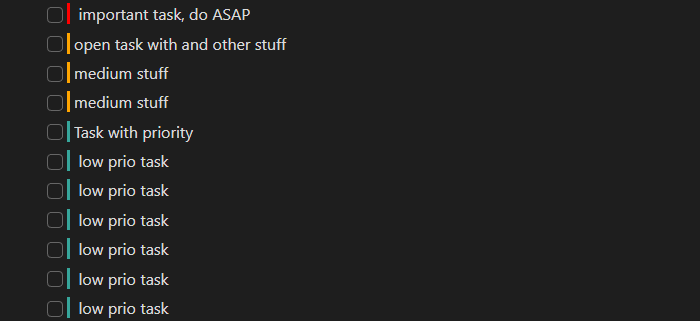
六、根据任务属性自定义渲染
这个案例中,根据任务描述文本中定义的内联属性 priority 的值 high | medium | low 来添加不同的标识样式。
// define pages
const pages = dv.pages('"10 Example Data/projects"')
// OPEN TASKS
const tasks = pages.file.tasks.where(t => t.priority && !t.completed)
// priorities color
const red = "<span style='border-left: 3px solid red;'> </span>"
const orange = "<span style='border-left: 3px solid orange;'> </span>"
const green = "<span style='border-left: 3px solid rgb(55 166 155);'> </span>"
// regex to remove the field priority in text
const regex = /\[priority[^\]]+\]/g
// assign colors according to priority
for (let task of tasks){
task.visual = "";
if (task.priority === "high") {
task.visual = red
} else if (task.priority === "medium") {
task.visual = orange
} else if (task.priority === "low") {
task.visual = green
}
task.visual += task.text.replace(regex, "");
}
// render open tasks sorted after priority
const order = [ "low", "medium", "high"]
dv.taskList(tasks.sort((a, b) => order.indexOf(b.priority) - order.indexOf(a.priority)), false)
结果:
进一步阅读:Colorcode tasks based on meta data – Dataview Example Vault (s-blu.github.io)