- Obsidian插件Dataview —— 安装与设置(一)
- Obsidian插件Dataview —— YAML简介(二)
- Obsidian插件Dataview —— 认识属性(三)
- Obsidian插件Dataview —— 数据查询(四)
- Obsidian插件Dataview —— DQL查询语言详解(五)
- Obsidian插件DataviewJS —— TypeScript速成(六)
- Obsidian插件Dataview —— 深入理解DataviewJS(七)
- Obsidian插件Dataview —— JavaScript API 快速入门(八)
- Obsidian插件Dataview —— DataArray接口介绍(九)
- Obsidian插件Dataview —— Dataviewjs JavaScript API 进阶用法(十)
- Obsidian插件Dataview —— Luxon库介绍(十一)
- Obsidian插件Dataview —— 实用案例讲解(初级篇)(十二)
- Obsidian插件Dataview —— 实用案例讲解(中级篇)(十三)
- Obsidian插件Dataview —— 实用案例讲解(高级篇)(十四)
- Obsidian插件Dataview —— 函数合集(十五)
目录
- 一、Query 查询
- 二、渲染
- 三、视图
- 四、Utility
- 1. Dv.Array (value)
- 2. Dv.IsArray (value)
- 3. Dv.FileLink (path, [embed?], [display-name])
- 4. Dv.SectionLink (path, section, [embed?], [display?])
- 5. Dv.BlockLink (path, blockId, [embed?], [display?])
- 6. Dv.Date (text)
- 7. Dv.Duration (text)
- 8. Dv.Compare (a, b)
- 9. Dv.Equal (a, b)
- 10. Dv.Clone (value)
- 11. Dv.Parse (value)
- 五、File I/O
- 六、Query Evaluation
一、Query 查询
1. Dv.Current ()🍇查询当前页
查询的是,查询语句所在的页面内容。
2. Dv.Pages (source)🍈查询指定页
[!success] 查询来源 用 dataview 的 from 来理解就可以了,可以是多种对象
dv.pages() //查询库全部文件,类似于 from ""
dv.pages("#books") //查询所有的 #books 标签,类似于 from #books
dv.pages('"folder"') //查询所有的文件夹 "folder",必须有""双引号
dv.pages("#yes or -#no") //查询标签#yes 或者 不包含#no标签的
dv.pages('"folder" or #tag')//查询文件夹"folder" 或者 标签#tag
dv.pages()
[!warnning] 易错点
- pages 里面的内容要用单引号包裹
''- 文件夹名称要有双引号”文件夹”,完整语法应该是'”文件夹”‘, 否则无效
3. Dv.PagePaths (source)🍉查询对象
与 dv.pages 相同,但只返回与给定源匹配的页面路径的数据数组
dv.pagePaths(“#books”) //页面路径中包含#books标签
4. Dv.Page (path)🍊查询路径
将简单路径或链接映射到完整页面对象,该对象包括所有页面字段。自动进行链接解析,如果不存在,将自动计算出扩展名
dv.page(“Index”) => 查询文件路径为 /Index 文件夹
dv.page(“books/The Raisin.md”) => 查询文件路径为 /books/The Raisin.md
)
二、渲染
1. Dv.El (element, text) 任意元素
呈现给定 html 元素中的任意文本。
dv.el(“b”, “This is some bold text”);
您可以通过 cls 指定要添加到元素的自定义类,通过 attr 指定其他属性:
dv.el(“b”, “This is some text”, { cls: “dataview dataview-class”, attr: { alt: “Nice!” } });
2.Dv.Header (level, text) 标题
使用给定文本呈现级别为 1 – 6 的标题。
dv.header(1, “Big!”);
dv.header(6, “Tiny”);
3. Dv.Paragraph (text) 段落 p
渲染段落中的任意文本。
dv.paragraph(“This is some text”);
4. Dv.Span (text) span 元素
渲染范围内的任意文本(不像段落那样在上方/下方填充)。
dv.span(“This is some text”);
5. Dv.Execute (source)🍉执行 dataview 查询
执行任意数据视图查询并将视图嵌入到当前页面中。
dv.execute(“LIST FROM #tag”);
dv.execute(“TABLE field1, field2 FROM #thing”);
6. Dv.ExecuteJs (source)🥭执行 dataviewjs 查询
执行任意 dataviewjs 查询并将视图嵌入到当前页面中。
dv.executeJs(“dv.list([1, 2, 3])”);
7. Dv.View (path, input)
允许自定义视图的复杂功能。将尝试加载给定路径下的 JavaScript 文件,传递 dv 和 input 并允许其执行。这使您可以跨多个页面重用自定义视图代码。请注意,这是一个异步函数,因为它涉及到文件 I/O-请确保 await 结果!
await dv.view(“views/custom”, { arg1: …, arg2: … });
如果还想在视图中包含自定义 CSS,则可以传递一个路径,指向包含 view.js 和 view.css 的文件夹; CSS 将自动添加到视图中:
views/custom
-> view.js
-> view.css
视图脚本可以访问 dv 对象(API 对象)和一个 input 对象,后者与 dv.view() 的第二个参数完全相同。
三、视图
接受普通数组和数据数组
1. Dv.List (elements) 列表视图
呈现元素的数据视图列表; 接受普通数组和数据数组
dv.list([1, 2, 3]) => list of 1, 2, 3
dv.list(dv.pages().file.name) => list of all file names
dv.list(dv.pages().file.link) => list of all file links
dv.list(dv.pages(“#book”).where(p => p.rating > 7)) => list of all books with rating greater than 7
2. Dv.TaskList (tasks, groupByFile) 任务列表视图
呈现由 page.file.tasks 获取的 Task 对象的数据视图列表。只需要第一个参数; 如果提供了第二个参数 groupByFile (并且为真),则任务将根据它们来自的文件自动分组。
// List all tasks from pages marked '#project'
dv.taskList(dv.pages("#project").file.tasks)
// List all *uncompleted* tasks from pages marked #project
dv.taskList(dv.pages("#project").file.tasks
.where(t => !t.completed))
// List all tasks tagged with '#tag' from pages marked #project
dv.taskList(dv.pages("#project").file.tasks
.where(t => t.text.includes("#tag")))
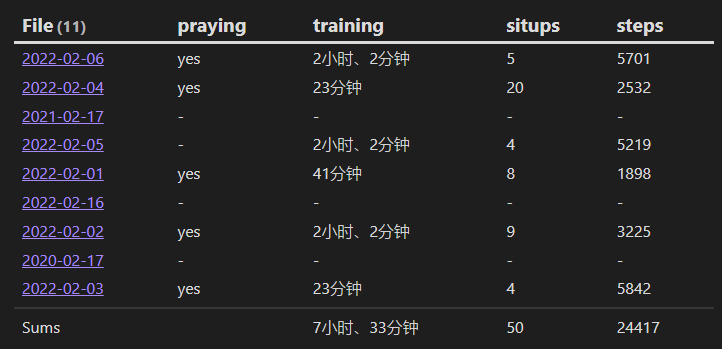
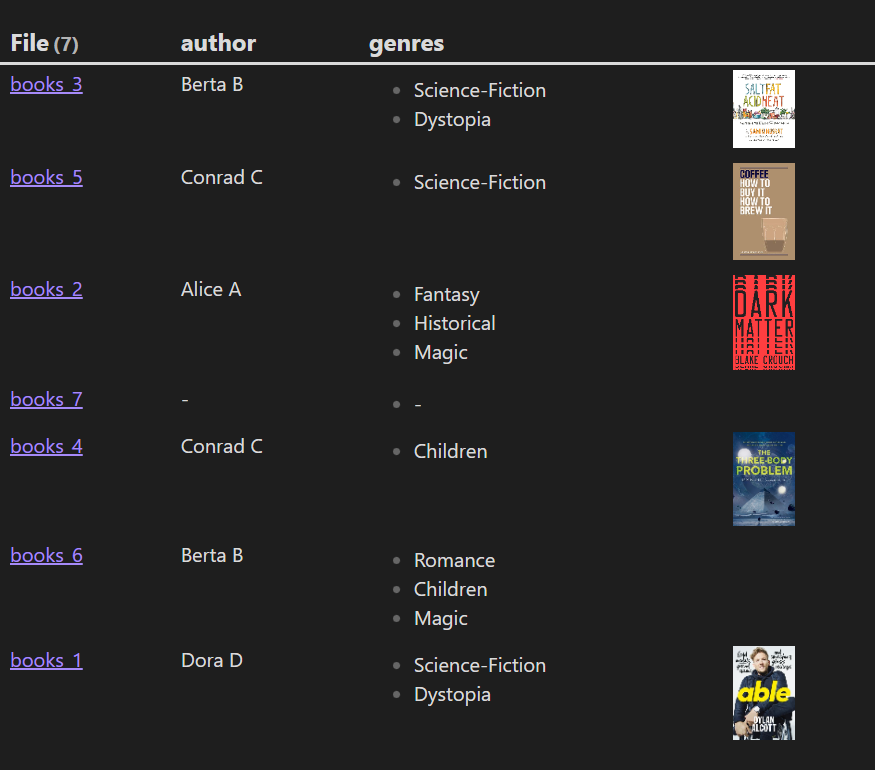
3. Dv.Table (headers, elements) 表格视图
使用给定的标题列表和二维元素数组呈现数据视图表。
// Render a simple table of book info sorted by rating.
dv.table([“File”, “Genre”, “Time Read”, “Rating”], dv.pages(“#book”)
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b[“time-read”], b.rating]))
4. Markdown Dataviews 视图 markdown
呈现为普通 Markdown 字符串的函数,然后您可以根据需要呈现或操作该字符串。
// Render a simple table of book info sorted by rating.
const table = dv.markdownTable([“File”, “Genre”, “Time Read”, “Rating”], dv.pages(“#book”)
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b[“time-read”], b.rating]))
dv.paragraph(table);
5. Dv.MarkdownTable (headers, values) md 表格
等效于 dv.table() ,它呈现具有给定标题列表和二维元素数组的表,但返回普通 Markdown。
6. Dv.MarkdownList (values) md 列表
等效于 dv.list() ,它呈现给定元素的列表,但返回纯 Markdown。
const markdown = dv.markdownList([1, 2, 3]);
dv.paragraph(markdown);
7. Dv.MarkdownTaskList (tasks) md 任务列表
等效于 dv.taskList() ,它呈现任务列表,但返回纯 Markdown。
const markdown = dv.markdownTaskList(dv.pages(“#project”).file.tasks);
dv.paragraph(markdown);
四、Utility
1. Dv.Array (value)
将给定值或数组转换为数据视图数据数组。如果该值已经是数据数组,则返回未更改的值。
dv.array([1, 2, 3]) => dataview data array [1, 2, 3]
2. Dv.IsArray (value)
如果给定值是数组或数据视图数组,则返回 true。
dv.isArray(dv.array([1, 2, 3])) => true
dv.isArray([1, 2, 3]) => true
dv.isArray({ x: 1 }) => false
3. Dv.FileLink (path, [embed?], [display-name])
将文本路径转换为数据视图 Link 对象; 你也可以选择指定链接是否嵌入以及它的显示名称。
dv.fileLink(“2021-08-08”) => link to file named “2021-08-08”
dv.fileLink(“book/The Raisin”, true) => embed link to “The Raisin”
dv.fileLink(“Test”, false, “Test File”) => link to file “Test” with display name “Test File”
4. Dv.SectionLink (path, section, [embed?], [display?])
将文本路径+节名称转换为数据视图 Link 对象; 你也可以选择指定链接是否被嵌入以及它的显示名称.
dv.sectionLink(“Index”, “Books”) => [[Index#Books]]
dv.sectionLink(“Index”, “Books”, false, “My Books”) => [[Index#Books|My Books]]
5. Dv.BlockLink (path, blockId, [embed?], [display?])
将文本路径+块 ID 转换为数据视图 Link 对象; 你也可以选择指定链接是否被嵌入以及它的显示名称.
dv.blockLink(“Notes”, “12gdhjg3”) => [[Index#^12gdhjg3]]
6. Dv.Date (text)
强制文本和链接到 luxon DateTime ; 如果提供了 DateTime ,则原样返回。
dv.date(“2021-08-08”) => DateTime for August 8th, 2021
dv.date(dv.fileLink(“2021-08-07”)) => dateTime for August 8th, 2021
7. Dv.Duration (text)
强制文本为 luxon Duration ;使用与数据视图持续时间类型相同的解析规则。
dv.duration(“8 minutes”) => Duration { 8 minutes }
dv.duration(“9 hours, 2 minutes, 3 seconds”) => Duration { 9 hours, 2 minutes, 3 seconds }
8. Dv.Compare (a, b)
根据 dataview 的默认比较规则比较任意两个 JavaScript 值; 如果您正在编写自定义比较器并希望回退到默认行为,则此选项非常有用。如果为 a < b ,则返回负值; 如果为 a = b ,则返回 0; 如果为 a > b ,则返回正值。
dv.compare(1, 2) = -1
dv.compare(“yes”, “no”) = 1
dv.compare({ what: 0 }, { what: 0 }) = 0
9. Dv.Equal (a, b)
比较两个任意 JavaScript 值,如果根据 Dataview 的默认比较规则相等,则返回 true。
dv.equal(1, 2) = false
dv.equal(1, 1) = true
10. Dv.Clone (value)
深度克隆任何数据视图值,包括日期、数组和链接。
dv.clone(1) = 1
dv.clone({ a: 1 }) = { a: 1 }
11. Dv.Parse (value)
五、File I/O
1. ⌛ dv.Io.Csv (path, [origin-file])
从给定路径(链接或字符串)加载 CSV。相对路径将相对于可选的原始文件进行解析(如果未提供,则默认为当前文件)。
返回一个数据视图数组,每个元素包含一个对象的 CSV 值; 如果文件不存在,则返回 undefined 。
await dv.io.csv(“hello.csv”) => [{ column1: …, column2: …}, …]
2. ⌛ dv.Io.Load (path, [origin-file])
异步加载给定路径(链接或字符串)的内容。相对路径将相对于可选的原始文件进行解析(如果未提供,则默认为当前文件)。返回文件的字符串内容,如果文件不存在,则返回 undefined 。
await dv.io.load(“File”) => “# File\nThis is an example file…”
3. Dv.Io.Normalize (path, [origin-file])
将相对链接或路径转换为绝对路径。如果提供了 origin-file ,则解析过程就像解析来自该文件的链接一样; 如果不是,则相对于当前文件解析路径。
dv.io.normalize(“Test”) => “dataview/test/Test.md”, if inside “dataview/test”
dv.io.normalize(“Test”, “dataview/test2/Index.md”) => “dataview/test2/Test.md”, irrespective of the current file
六、Query Evaluation
1. ⌛ dv.Query (source, [file, settings])
执行数据视图查询并将结果作为结构化返回返回。此函数的返回类型因执行的查询类型而异,但始终是一个带有 type 的对象,表示返回类型。这个版本的 query 返回一个结果类型–您可能需要 tryQuery ,它会在查询执行失败时抛出一个错误。
await dv.query(“LIST FROM #tag”) =>
Success { type: “list”, values: [value1, value2, …] }
await dv.query(TABLE WITHOUT ID file.name, value FROM "path") =>
Success { type: “table”, headers: [“file.name”, “value”], values: [[“A”, 1], [“B”, 2]] }
await dv.query(“TASK WHERE due”) =>
Success { type: “task”, values: [task1, task2, …]}
dv.query 接受两个附加的可选参数:1. file :解析查询的文件路径(如果引用 this )。默认为当前文件。2. settings :运行查询的执行设置。这在很大程度上是一个高级用例(我建议您直接检查 API 实现以查看所有可用选项)。
2. ⌛ dv.TryQuery (source, [file, settings])
与 dv.query 完全相同,但在短脚本中更方便,因为执行失败将作为 JavaScript 异常而不是结果类型引发。
⌛ dv.queryMarkdown(source, [file], [settings]) 第0号
3. ⌛ dv.QueryMarkdown (source, [file], [settings])
等效于 dv.query() ,但返回渲染的 Markdown。
await dv.queryMarkdown(“LIST FROM #tag”) =>
Success { “- [[Page 1]]\n- [[Page 2]]” }
4. ⌛ dv.TryQueryMarkdown (source, [file], [settings])
与 dv.queryMarkdown() 完全相同,但在解析失败时抛出错误。
dv.tryEvaluate(expression, [context])
5. Dv.TryEvaluate (expression, [context])
计算任意数据视图表达式(如 2 + 2 或 link("text") 或 x * 9 ); 在分析或计算失败时抛出 Error 。 this 是始终可用的隐式变量,它引用当前文件。
dv.tryEvaluate(“2 + 2”) => 4
dv.tryEvaluate(“x + 2”, {x: 3}) => 5
dv.tryEvaluate(“length(this.file.tasks)”) => number of tasks in the current file
6. Dv.Evaluate (expression, [context])
计算任意数据视图表达式(如 2 + 2 、 link("text") 或 x * 9 ),返回结果的 Result 对象。您可以通过选中 result.successful (然后获取 result.value 或 result.error )来展开结果类型。如果您想要一个在求值失败时抛出错误的更简单的 API,请使用 dv.tryEvaluate 。
dv.evaluate(“2 + 2”) => Successful { value: 4 }
dv.evaluate(“2 +”) => Failure { error: “Failed to parse … ” }