页面参数
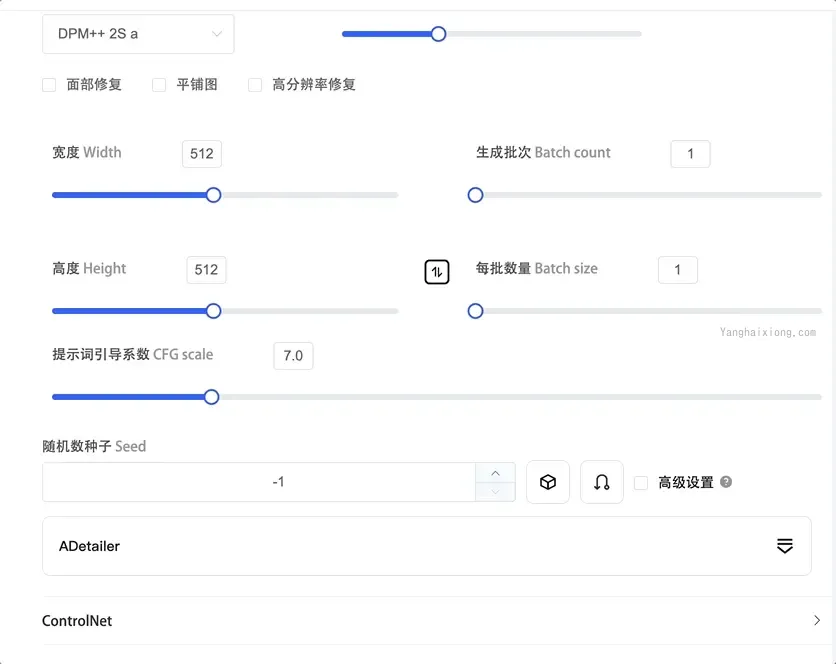
Stable Diffusion checkpoint:选择具体的模型Prompt:正向提示词,描述你想要的图片,比如:girl,long hair,black clothes,big eyes(长发黑衣服大眼睛的女孩)。@注意: 不支持中文Negative prompt:反向提示次,不想要在图像中出现的词,比如:low quality(低质量)。Sampling Method:抽样法,常用于去噪,内置多种算法可供选择。比如DPM++ 2M Karras,可以很好地平衡了速度和质量。Sampling Steps: 采样步骤数。虽然越多越好,但是值越大生成的时间越长。大部分情况选择:20 ~ 25。Width & Height:输出图像的大小长和宽。长宽也不是随意设置; 目前使用 v1 模型时,至少将一变设置为512。目前已知可选的组合有:512*512、512*768、768*512Batch Count: 批次数量。Batch size:每一批次要生成的图像数量。CFG scale: 用于控制模型生成的图片,和提示词的符合度。默认为7,数值越小AI自由发挥的空间就越大,数值越大相对来说就越刻板 (严格按照提示词);Seed:指定一个随机种子,用于初始化图像生成过程。相同的种子值每次都会产生相同的图像集,这对于再现性和一致性很有用,如果将值设置为 -1,则每次运行都会生成一个随机种子。Hires.Fix: 高清修复,主要是提高生成的图像的分辨率,注意: 开启后生成图片会很慢; 其他选项说明:Upscaler:指的是放大算法,内置了很多算法,其中R-ESRGAN 4x+:擅长写实图片、R-ESRGAN 4x+ Anime6B:擅长二次元图片,Hires setps: 高清修复的步数和Sampling Steps代表的意义一样;Denoising strength: 重绘幅度,AI的自由发挥空间,值越大 AI 就越放飞自我,值越小就越按照原图重绘;Upscale by: 放大的倍数,和下面两个互斥;Resize width to:指的是把图片放大后,宽度的像素;Resize height to: 指的是把图片放大后,高度的像素;
更多配置说明可参见文档: https://stable-diffusion.org.cn/t/topic/22
![v2-d9d83475a6871b1749cfc079b998fab1_b.webp]()
启动参数
配置参数
-h, --help:显示帮助信息并退出。
--exit:安装后立即终止。
--data-dir:指定存储所有用户数据的基本路径,默认为"./"。
--config:用于构建模型的配置文件路径,默认为 "configs/stable-diffusion/v1-inference.yaml"。
--ckpt:稳定扩散模型的检查点路径;如果指定,该检查点将被添加到检查点列表并加载。
--ckpt-dir:稳定扩散检查点的目录路径。
--no-download-sd-model:即使没有找到模型,也不下载 SD1.5 模型。
--vae-dir:变分自编码器模型的路径。
--gfpgan-dir:GFPGAN 目录。
--gfpgan-model:GFPGAN 模型文件名。
--codeformer-models-path:Codeformer 模型文件的目录路径。
--gfpgan-models-path:GFPGAN 模型文件的目录路径。
--esrgan-models-path:ESRGAN 模型文件的目录路径。
--bsrgan-models-path:BSRGAN 模型文件的目录路径。
--realesrgan-models-path:RealESRGAN 模型文件的目录路径。
--scunet-models-path:ScuNET 模型文件的目录路径。
--swinir-models-path:SwinIR 和 SwinIR v2 模型文件的目录路径。
--ldsr-models-path:LDSR 模型文件的目录路径。
--lora-dir:Lora 网络的目录路径。
--clip-models-path:CLIP 模型文件的目录路径。
--embeddings-dir:用于文本逆向的嵌入目录,默认为 "embeddings"。
--textual-inversion-templates-dir:文本逆向模板的目录。
--hypernetwork-dir:超网络目录。
--localizations-dir:本地化目录。
--styles-file:用于样式的文件名,默认为 "styles.csv"。
--ui-config-file:用于 UI 配置的文件名,默认为 "ui-config.json"。
--no-progressbar-hiding:不隐藏 Gradio UI 中的进度条(默认隐藏,因为在浏览器中使用硬件加速会降低机器学习速度)。
--max-batch-count:UI 的最大批次计数值,默认为 16。
--ui-settings-file:用于 UI 设置的文件名,默认为 "config.json"。
--allow-code:允许从 Web UI 执行自定义脚本。
--share:使用 Gradio 的 share=True,并使 UI 通过其网站访问(对我来说不起作用,但您可能会更幸运)。
--listen:使用 0.0.0.0 作为服务器名称启动 Gradio,允许响应网络请求。
--port:使用给定的服务器端口启动 Gradio,需要根/管理员权限才能使用 1024 以下的端口,默认为 7860(如果可用)。 34. --hide-ui-dir-config:从 Web UI 中隐藏目录配置。
--freeze-settings:禁用编辑设置。
--enable-insecure-extension-access:无论其他选项如何,都启用扩展选项卡。
--gradio-debug:使用--debug 选项启动 Gradio。
--gradio-auth:设置 Gradio 身份验证,如 "username:password";或逗号分隔多个,如 "u1:p1,u2:p2,u3:p3"。
--gradio-auth-path:设置 Gradio 身份验证文件路径,例如 "/path/to/auth/file",与--gradio-auth 的格式相同。
--disable-console-progressbars:不在控制台输出进度条。
--enable-console-prompts:在使用 txt2img 和 img2img 生成时,在控制台打印提示。
--api:使用 API 启动 Web UI。
--api-auth:设置 API 身份验证,如 "username:password";或逗号分隔多个,如 "u1:p1,u2:p2,u3:p3"。
--api-log:启用所有 API 请求的日志记录。
--nowebui:仅启动 API,不启动 UI。
--ui-debug-mode:不加载模型以快速启动 UI。
--device-id:选择要使用的默认 CUDA 设备(可能需要在此之前设置 CUDA_VISIBLE_DEVICES=0,1 等环境变量)。
--administrator:管理员权限。
--cors-allow-origins:以逗号分隔的列表形式允许的 CORS 来源(无空格)。
--cors-allow-origins-regex:以单个正则表达式的形式允许的 CORS 来源。
--tls-keyfile:部分启用 TLS,需要--tls-certfile 才能完全生效。
--tls-certfile:部分启用 TLS,需要--tls-keyfile 才能完全生效。
--server-name:设置服务器主机名。
--gradio-queue:使用 Gradio 队列;实验性选项;破坏重新启动 UI 按钮。
--skip-version-check:不检查 torch 和 xformers 的版本。
--no-hashing:禁用检查点的 sha256 哈希,以提高加载性能。
通用参数
--autolaunch:在启动时使用系统的默认浏览器打开 WebUI URL。
--theme:在 WebUI 中使用指定的主题(“light”或“dark”)。如果未指定,则使用浏览器的默认主题。
--use-textbox-seed:在 UI 中使用文本框输入种子(没有上/下箭头,但可以输入长种子)。
--disable-safe-unpickle:禁用对 PyTorch 模型的恶意代码检查。
--ngrok:用于 ngrok 的自动令牌,是 gradio --share 的替代方案。
--ngrok-region:ngrok 应该在其中启动的区域。
性能参数
--xformers:启用 xformers 以加速跨注意层。
--reinstall-xformers:强制重新安装 xformers。在升级后使用,但升级后请移除,否则将一直重装 xformers。
--force-enable-xformers:无论检查代码是否认为可以运行,都强制启用 xformers 的跨注意层;如果运行失败,请勿提交错误报告。
--opt-split-attention:强制启用 Doggettx 的跨注意层优化。默认情况下,对于启用 CUDA 的系统,此选项已开启。
--opt-split-attention-invokeai:强制启用 InvokeAI 的跨注意层优化。默认情况下,当 CUDA 不可用时,此选项已开启。
--opt-split-attention-v1:启用旧版本的分割注意力优化,该版本不会消耗所有可用的显存。
--opt-sub-quad-attention:启用内存高效的子二次交叉注意力层优化。
--sub-quad-q-chunk-size:子二次交叉注意力层优化使用的查询块大小。
--sub-quad-kv-chunk-size:子二次交叉注意力层优化使用的 kv 块大小。
--sub-quad-chunk-threshold:子二次交叉注意力层优化使用的显存使用率阈值。
--opt-channelslast:为 4d 张量启用备选布局,仅在具有 Tensor 核心的 Nvidia 显卡(16xx 及更高版本)上可能导致更快的推理。
--disable-opt-split-attention:强制禁用跨注意层优化。
--disable-nan-check:不检查生成的图像/潜在空间是否包含 nan 值;在持续集成中运行时无需检查点。
--use-cpu:对指定模块使用 CPU 作为 torch 设备。
--no-half:不将模型切换为 16 位浮点数。
--precision:以此精度进行评估。
--no-half-vae:不将 VAE 模型切换为 16 位浮点数。
--upcast-sampling:向上采样。与 --no-half 无效。通常产生与 --no-half 类似的结果,但在使用较少内存的情况下性能更好。
--medvram:启用稳定扩散模型优化,牺牲一点速度以减少显存使用。
--lowvram:启用稳定扩散模型优化,牺牲大量速度以极低的显存使用。
--lowram:将稳定扩散检查点权重加载到显存而非 RAM。
--always-batch-cond-uncond:禁用使用 --medvram 或 --lowvram 时为节省内存而启用的条件/无条件批处理。




